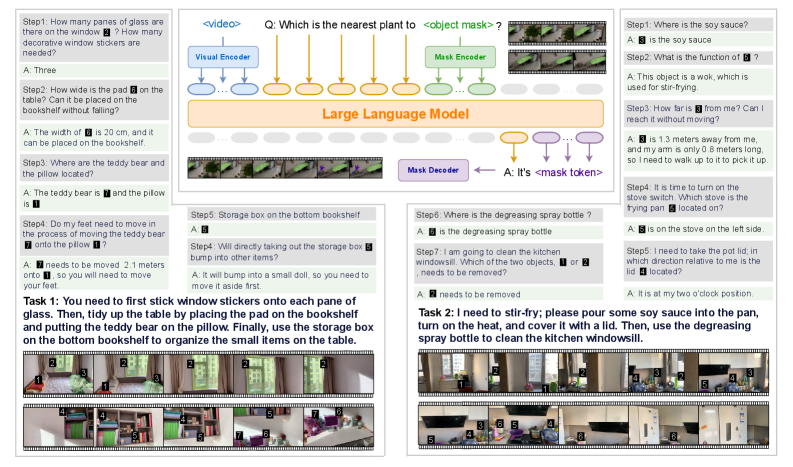
## Flowchart: Multimodal Question-Answering System with Object Masking
### Overview
The image depicts a technical diagram of a multimodal question-answering system that integrates visual processing, object masking, and natural language understanding. The system processes visual inputs (e.g., images/videos) to answer contextual questions about object locations, quantities, and spatial relationships. Two example tasks demonstrate practical applications: organizing items on a bookshelf and preparing a kitchen task.
---
### Components/Axes
1. **Central Diagram**:
- **Visual Encoder**: Processes raw visual input (images/videos).
- **Mask Encoder**: Identifies and isolates specific objects in the visual input (e.g., "object mask").
- **Large Language Model (LLM)**: Integrates masked visual data with textual queries to generate answers.
- **Mask Decoder**: Converts masked tokens into natural language responses.
- **Arrows**: Indicate data flow (e.g., visual input → mask encoder → LLM → mask decoder).
2. **Left Panel**:
- **Steps 1–7**: Textual Q&A examples with numbered objects (e.g., "How many panes of glass are there on the window?").
- **Objects**: Labeled with numbers (e.g., "3" for soy sauce, "6" for storage box).
3. **Right Panel**:
- **Tasks 1–2**: Practical instructions with step-by-step actions (e.g., "stick window stickers," "stir-fry with soy sauce").
- **Objects**: Labeled with numbers (e.g., "5" for storage box, "7" for pot lid).
4. **Color Coding**:
- **Blue**: Visual Encoder.
- **Green**: Mask Encoder.
- **Orange**: Large Language Model.
- **Purple**: Mask Decoder.
---
### Detailed Analysis
1. **Visual Encoder**:
- Inputs: Images/videos (e.g., kitchen scenes, bookshelf arrangements).
- Output: Feature vectors for object detection.
2. **Mask Encoder**:
- Identifies objects via bounding boxes (e.g., "object mask" for soy sauce).
- Output: Mask tokens (e.g., `<object mask>`).
3. **Large Language Model**:
- Integrates masked visual tokens with textual queries (e.g., "Which is the nearest plant to <object mask>?").
- Output: Contextualized answers (e.g., "It’s 1.3 meters away").
4. **Mask Decoder**:
- Converts mask tokens into natural language (e.g., "A: It’s <mask token>" → "A: It’s 1.3 meters away").
5. **Tasks**:
- **Task 1**: Organizing items (e.g., placing glass panes, moving a teddy bear).
- **Task 2**: Cooking instructions (e.g., pouring soy sauce, using a spray bottle).
---
### Key Observations
1. **Object Labeling**: Objects are consistently labeled with numbers (e.g., "3" for soy sauce, "6" for storage box) across steps and tasks.
2. **Spatial Reasoning**: Questions require understanding relative positions (e.g., "nearest plant to <object mask>").
3. **Temporal Flow**: Tasks involve sequential actions (e.g., "pour soy sauce → cover with lid → spray bottle").
4. **Modular Design**: The system separates visual processing (encoders) from language processing (LLM, decoder).
---
### Interpretation
This system demonstrates a hybrid approach to multimodal reasoning:
- **Visual-Language Integration**: The LLM bridges visual object masks (e.g., soy sauce) with textual queries, enabling context-aware answers.
- **Practical Applications**: Tasks 1 and 2 show real-world use cases, such as home organization and cooking, where spatial and temporal reasoning are critical.
- **Scalability**: The modular architecture (encoders, LLM, decoder) suggests adaptability to diverse inputs (e.g., different objects, environments).
The system’s strength lies in its ability to handle ambiguous queries (e.g., "Which stove is the frying pan located on?") by combining visual grounding with linguistic context. However, the reliance on numbered object labels implies a need for precise annotation in training data.