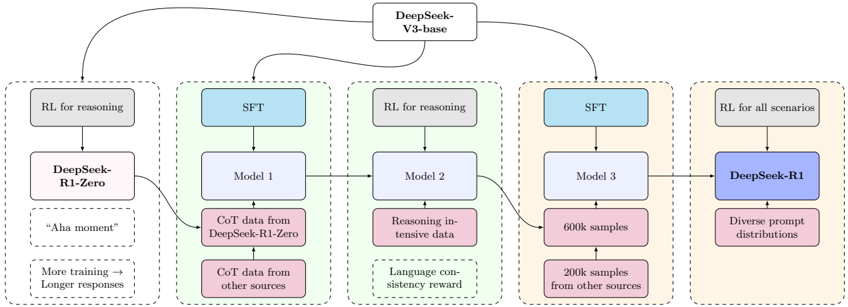
## Diagram: DeepSeek Model Training Flow
### Overview
The image is a flowchart illustrating the training process of the DeepSeek-R1 model, starting from the DeepSeek-V3-base model. The diagram shows the flow of data and training steps through various stages, including Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT).
### Components/Axes
* **Nodes:** Rectangular boxes representing models, data, or training steps.
* **Edges:** Arrows indicating the flow of data or the sequence of training.
* **Regions:** The diagram is divided into five regions, each enclosed by a dashed line.
* **Labels:** Text within the boxes describing the model, data, or training step.
**Nodes and Labels:**
* **Top Center:** "DeepSeek-V3-base"
* **Region 1 (Leftmost):**
* "RL for reasoning" (Gray box)
* "DeepSeek-R1-Zero" (Pink box)
* "Aha moment" (Pink box)
* "More training -> Longer responses" (Pink box)
* **Region 2:**
* "SFT" (Blue box)
* "Model 1" (Light Blue box)
* "CoT data from DeepSeek-R1-Zero" (Pink box)
* "CoT data from other sources" (Pink box)
* **Region 3:**
* "RL for reasoning" (Gray box)
* "Model 2" (Light Blue box)
* "Reasoning intensive data" (Pink box)
* "Language consistency reward" (Pink box)
* **Region 4:**
* "SFT" (Blue box)
* "Model 3" (Light Blue box)
* "600k samples" (Pink box)
* "200k samples from other sources" (Pink box)
* **Region 5 (Rightmost):**
* "RL for all scenarios" (Gray box)
* "DeepSeek-R1" (Blue box)
* "Diverse prompt distributions" (Pink box)
### Detailed Analysis or Content Details
1. **DeepSeek-V3-base:** The process starts with the DeepSeek-V3-base model.
2. **Region 1:**
* The DeepSeek-V3-base model undergoes Reinforcement Learning (RL) for reasoning.
* This results in the "DeepSeek-R1-Zero" model.
* The "Aha moment" and "More training -> Longer responses" indicate characteristics or outcomes of this stage.
3. **Region 2:**
* The DeepSeek-V3-base model also undergoes Supervised Fine-Tuning (SFT), resulting in "Model 1".
* "Model 1" is trained using "CoT data from DeepSeek-R1-Zero" and "CoT data from other sources".
4. **Region 3:**
* "Model 1" is further used to create "Model 2".
* "Model 2" undergoes Reinforcement Learning (RL) for reasoning.
* "Model 2" is trained using "Reasoning intensive data" and "Language consistency reward".
5. **Region 4:**
* "Model 2" is further used to create "Model 3".
* "Model 3" undergoes Supervised Fine-Tuning (SFT).
* "Model 3" is trained using "600k samples" and "200k samples from other sources".
6. **Region 5:**
* "Model 3" is used to create "DeepSeek-R1".
* "DeepSeek-R1" undergoes Reinforcement Learning (RL) for all scenarios.
* "DeepSeek-R1" is trained using "Diverse prompt distributions".
### Key Observations
* The diagram shows a multi-stage training process involving both Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT).
* The process starts with a base model (DeepSeek-V3-base) and culminates in the DeepSeek-R1 model.
* The diagram highlights the use of different types of data (CoT data, Reasoning intensive data, Diverse prompt distributions) at various stages of training.
* The diagram shows a flow of data and models from left to right, with feedback loops from DeepSeek-R1-Zero to Model 1.
### Interpretation
The diagram illustrates the complex training pipeline used to develop the DeepSeek-R1 model. The combination of RL and SFT, along with the use of diverse training data, suggests an effort to create a robust and versatile model capable of handling a wide range of scenarios. The feedback loop from DeepSeek-R1-Zero to Model 1 indicates an iterative process where the model's performance is refined over time. The "Aha moment" label suggests that the initial RL training of DeepSeek-R1-Zero leads to a significant breakthrough in the model's reasoning abilities. The "More training -> Longer responses" label suggests that further training leads to more detailed and comprehensive responses from the model. The use of "Language consistency reward" suggests an effort to ensure that the model's responses are coherent and consistent.