\n
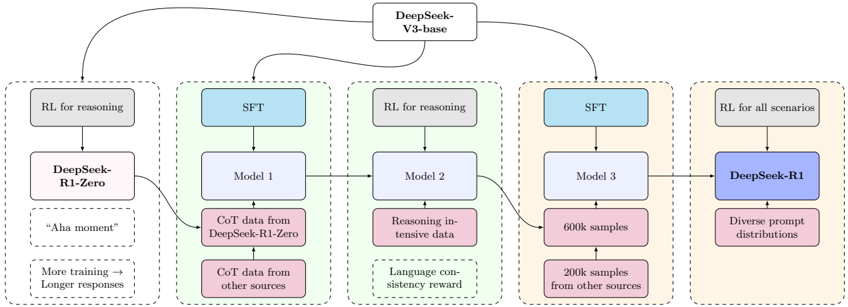
## Diagram: DeepSeek Model Training Pipeline
### Overview
The image depicts a diagram illustrating the training pipeline for the DeepSeek models, progressing from a base model (DeepSeek-V3-base) through several stages of supervised fine-tuning (SFT) and reinforcement learning (RL) to arrive at the final model, DeepSeek-R1. The diagram shows the data sources and processes involved in each stage.
### Components/Axes
The diagram consists of several rectangular blocks representing different model versions and training stages. Arrows indicate the flow of data and model evolution. Key components include:
* **DeepSeek-V3-base:** The initial base model. Located at the top-center of the diagram.
* **DeepSeek-R1-Zero:** An intermediate model trained with RL for reasoning. Located on the left side of the diagram.
* **Model 1, Model 2, Model 3:** Intermediate models undergoing SFT and RL training. Arranged horizontally in the center of the diagram.
* **DeepSeek-R1:** The final, refined model. Located on the right side of the diagram.
* **Data Sources:** Various data sources are represented by smaller rectangles connected to the models, including "CoT data from DeepSeek-R1-Zero", "CoT data from other sources", "Reasoning intensive data", "Language consistency reward", "600k samples", "200k samples from other sources", and "Diverse prompt distributions".
* **Training Methods:** "RL for reasoning", "SFT", and "RL for all scenarios" are indicated as training methods applied to the models.
### Detailed Analysis or Content Details
The diagram illustrates a multi-stage training process:
1. **DeepSeek-V3-base** is the starting point.
2. A branch leads to **DeepSeek-R1-Zero**, trained using "RL for reasoning". This model is associated with the text "‘Aha moment’" and "More training -> Longer responses".
3. Another branch from DeepSeek-V3-base leads to **Model 1**, which undergoes SFT using "CoT data from DeepSeek-R1-Zero" and "CoT data from other sources".
4. **Model 1** then feeds into **Model 2**, trained using "RL for reasoning" and "Reasoning intensive data" with a "Language consistency reward".
5. **Model 2** then feeds into **Model 3**, which undergoes SFT using "600k samples" and "200k samples from other sources".
6. Finally, **Model 3** leads to **DeepSeek-R1**, trained using "RL for all scenarios" and "Diverse prompt distributions".
The arrows indicate a sequential flow of information and model refinement. The diagram does not provide numerical data or specific parameter values.
### Key Observations
* The pipeline emphasizes iterative refinement through a combination of SFT and RL.
* The use of "CoT" (Chain-of-Thought) data suggests a focus on improving the model's reasoning capabilities.
* The increasing sample sizes (200k, 600k) in later stages indicate a scaling up of training data.
* The final stage focuses on "RL for all scenarios" and "Diverse prompt distributions", suggesting a goal of generalization and robustness.
### Interpretation
The diagram illustrates a sophisticated model training pipeline designed to enhance the reasoning and generalization abilities of the DeepSeek models. The iterative process, combining SFT and RL, suggests a strategy of gradually refining the model's behavior based on both supervised learning and reinforcement signals. The use of CoT data and reasoning-intensive data highlights a specific focus on improving the model's ability to perform complex reasoning tasks. The final stage, with its emphasis on diverse prompts and RL for all scenarios, suggests a goal of creating a robust and versatile model capable of handling a wide range of inputs and tasks. The "Aha moment" annotation associated with DeepSeek-R1-Zero suggests a breakthrough in the model's reasoning capabilities at that stage. The pipeline is a clear demonstration of a deliberate and structured approach to model development, prioritizing both performance and generalization.