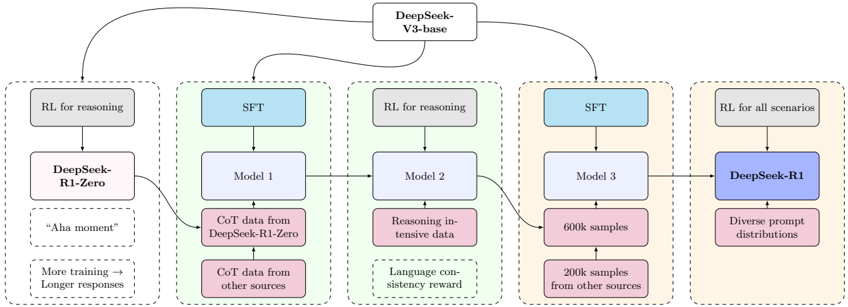
## Flowchart: DeepSeek Model Development Pipeline
### Overview
The flowchart illustrates the iterative development process of DeepSeek models, starting from foundational training (DeepSeek-R1-Zero) through multiple refinement stages (Model 1-3) to the final product (DeepSeek-R1). The pipeline integrates supervised fine-tuning (SFT), reinforcement learning (RL), and diverse data sources to enhance reasoning capabilities and language consistency.
### Components/Axes
1. **Central Node**: "DeepSeek-V3-base" (connects to all models)
2. **Left Column**:
- "DeepSeek-R1-Zero" (initial model)
- "RL for reasoning" (reasoning-focused training)
- Text: "Aha moment" (qualitative milestone)
- Text: "More training → Longer responses" (training outcome)
3. **Middle Column**:
- "SFT" (Supervised Fine-Tuning)
- "Model 1" (CoT data from DeepSeek-R1-Zero + other sources)
- "Model 2" (reasoning-intensive data + language consistency reward)
4. **Right Column**:
- "SFT" (Supervised Fine-Tuning)
- "Model 3" (600k samples + 200k samples from other sources)
- "DeepSeek-R1" (final model with diverse prompt distributions)
5. **Flow Arrows**: Connect nodes in a left-to-right progression with feedback loops to central "DeepSeek-V3-base"
### Detailed Analysis
- **DeepSeek-R1-Zero**: Initial model trained with RL for reasoning, marked by an "Aha moment" and longer responses after additional training.
- **Model 1**: Built using SFT with CoT (Chain-of-Thought) data from DeepSeek-R1-Zero and external sources.
- **Model 2**: Incorporates reasoning-intensive data and a language consistency reward mechanism.
- **Model 3**: Trained on 600k samples (primary source) and 200k samples from external datasets.
- **DeepSeek-R1**: Final model leveraging diverse prompt distributions and RL applied to all scenarios.
### Key Observations
1. **Iterative Refinement**: Each model (1→2→3) adds specialized data and training objectives.
2. **Data Diversity**: External data sources are integrated at multiple stages (Models 1, 2, 3).
3. **Scaling**: Sample sizes increase significantly (200k→600k) in later stages.
4. **Feedback Loops**: All models connect back to the central "DeepSeek-V3-base," suggesting iterative improvement cycles.
### Interpretation
The pipeline demonstrates a systematic approach to building advanced language models:
1. **Foundation**: DeepSeek-R1-Zero establishes baseline reasoning capabilities through RL.
2. **Specialization**: Models 1-3 progressively incorporate domain-specific data (CoT, reasoning-intensive) and quality metrics (language consistency).
3. **Scalability**: The jump from 200k to 600k samples in Model 3 suggests a focus on data quantity for final performance.
4. **Holistic Training**: The final model (DeepSeek-R1) integrates all prior improvements through diverse prompt engineering and comprehensive RL application.
This architecture highlights the importance of combining multiple training paradigms (SFT, RL) and data sources to achieve state-of-the-art language model performance.