\n
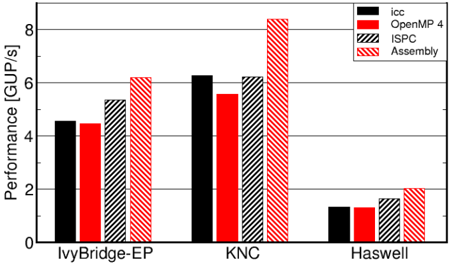
## Bar Chart: Performance Comparison of Different Compilers and Architectures
### Overview
This bar chart compares the performance (measured in GUP/s - Giga Updates Per Second) of different compilers (icc, OpenMP 4, ISPC, Assembly) across three different architectures (IvyBridge-EP, KNC, Haswell). Each architecture has four bars representing the performance of each compiler on that architecture.
### Components/Axes
* **X-axis:** Architecture - IvyBridge-EP, KNC, Haswell.
* **Y-axis:** Performance [GUP/s] - Scale ranges from 0 to 8, with increments of 2.
* **Legend:** Located in the top-right corner.
* Black: icc
* Red: OpenMP 4
* Gray (diagonal stripes): ISPC
* Red (cross-hatched): Assembly
### Detailed Analysis
Let's analyze the performance for each architecture and compiler:
**IvyBridge-EP:**
* icc (Black): Approximately 4.4 GUP/s.
* OpenMP 4 (Red): Approximately 4.8 GUP/s.
* ISPC (Gray): Approximately 5.4 GUP/s.
* Assembly (Red, cross-hatched): Approximately 6.2 GUP/s.
**KNC:**
* icc (Black): Approximately 6.2 GUP/s.
* OpenMP 4 (Red): Approximately 5.6 GUP/s.
* ISPC (Gray): Approximately 6.2 GUP/s.
* Assembly (Red, cross-hatched): Approximately 8.4 GUP/s.
**Haswell:**
* icc (Black): Approximately 1.6 GUP/s.
* OpenMP 4 (Red): Approximately 2.0 GUP/s.
* ISPC (Gray): Approximately 1.8 GUP/s.
* Assembly (Red, cross-hatched): Approximately 2.2 GUP/s.
### Key Observations
* Assembly consistently shows the highest performance across all three architectures.
* The KNC architecture generally exhibits higher performance than IvyBridge-EP and Haswell.
* Haswell consistently shows the lowest performance across all compilers.
* icc and ISPC show similar performance on KNC.
* OpenMP 4 performance is generally lower than ISPC and Assembly, but higher than icc on IvyBridge-EP.
### Interpretation
The data suggests that the Assembly compiler is the most effective for maximizing performance on these architectures. The KNC architecture is the most performant of the three tested. The Haswell architecture consistently underperforms compared to the other two. The differences in performance between compilers likely stem from their ability to effectively utilize the specific features and capabilities of each architecture. The consistent high performance of Assembly suggests it may be the most optimized for these workloads, potentially through direct hardware access or more efficient instruction scheduling. The lower performance of OpenMP 4 could indicate that the parallelization strategy is not optimally suited for these architectures or the specific workload. The data highlights the importance of compiler selection and architecture choice for achieving optimal performance in computational tasks. The significant performance gap between Haswell and the other architectures suggests that the workload is not well-suited for Haswell's design or that there are other limiting factors specific to that architecture.