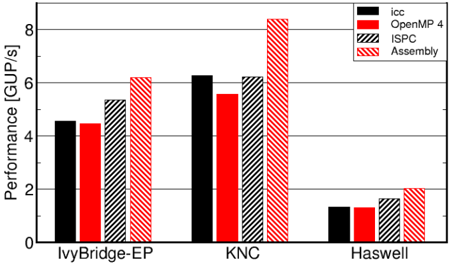
## Grouped Bar Chart: Performance Comparison Across Processors and Compilers
### Overview
The image is a grouped bar chart comparing computational performance, measured in Giga Updates Per Second (GUP/s), across three different processor architectures using four different programming/compiler approaches. The chart visually demonstrates significant performance variations based on both the hardware platform and the software optimization method.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis (Vertical):**
* **Label:** "Performance (GUP/s)"
* **Scale:** Linear scale from 0 to 8, with major tick marks at intervals of 2 (0, 2, 4, 6, 8).
* **X-Axis (Horizontal):**
* **Categories (Processor Architectures):** Three distinct groups labeled from left to right: "IvyBridge-EP", "KNC", and "Haswell".
* **Legend:**
* **Position:** Top-right corner of the chart area.
* **Entries (with visual encoding):**
1. `icc` - Solid black bar.
2. `OpenMP 4` - Solid red bar.
3. `ISPC` - Black bar with diagonal white stripes (hatching).
4. `Assembly` - Red bar with diagonal white stripes (hatching).
### Detailed Analysis
The performance for each compiler/method within each processor category is as follows (values are approximate visual estimates):
**1. IvyBridge-EP (Left Group):**
* **Trend:** Performance increases from left to right within the group (icc < OpenMP 4 < ISPC < Assembly).
* **Data Points:**
* `icc` (Solid Black): ~4.5 GUP/s
* `OpenMP 4` (Solid Red): ~4.4 GUP/s (marginally lower than icc)
* `ISPC` (Striped Black): ~5.3 GUP/s
* `Assembly` (Striped Red): ~6.2 GUP/s
**2. KNC (Middle Group):**
* **Trend:** Performance is highest for Assembly, with ISPC and icc performing similarly, and OpenMP 4 being the lowest in this group.
* **Data Points:**
* `icc` (Solid Black): ~6.3 GUP/s
* `OpenMP 4` (Solid Red): ~5.6 GUP/s
* `ISPC` (Striped Black): ~6.2 GUP/s (very close to icc)
* `Assembly` (Striped Red): ~8.4 GUP/s (the highest value in the entire chart)
**3. Haswell (Right Group):**
* **Trend:** All performance values are substantially lower than the other two architectures. The relative order is similar to IvyBridge-EP (Assembly highest, OpenMP 4 lowest).
* **Data Points:**
* `icc` (Solid Black): ~1.3 GUP/s
* `OpenMP 4` (Solid Red): ~1.3 GUP/s (approximately equal to icc)
* `ISPC` (Striped Black): ~1.7 GUP/s
* `Assembly` (Striped Red): ~2.0 GUP/s
### Key Observations
1. **Dominant Method:** The `Assembly` implementation (striped red bar) delivers the highest performance on all three processor architectures.
2. **Architecture Impact:** The KNC architecture achieves the highest absolute performance values, particularly with Assembly. The Haswell architecture shows a dramatic performance drop (roughly 3-4x lower) compared to IvyBridge-EP and KNC for all tested methods.
3. **Compiler/Method Hierarchy:** A consistent performance hierarchy is visible across architectures: `Assembly` > `ISPC` > `icc` ≈ `OpenMP 4`. The gap between `Assembly` and the others is most pronounced on KNC.
4. **Pattern Consistency:** The striped bars (`ISPC` and `Assembly`) consistently outperform their solid-color counterparts (`icc` and `OpenMP 4`) within each hardware group.
### Interpretation
This chart provides a clear technical comparison for performance optimization. The data suggests that for this specific computational workload (measured in GUP/s):
* **Low-level optimization matters:** Hand-tuned or highly specialized `Assembly` code provides a significant performance advantage over higher-level compilers (`icc`) and parallel programming models (`OpenMP 4`, `ISPC`). This advantage is not marginal; it represents a 20-50%+ improvement over the next best method in most cases.
* **Hardware-software co-design is critical:** The KNC architecture, likely a many-core processor (Intel Xeon Phi), shows the greatest benefit from optimized code, indicating its performance is highly sensitive to software tuning. The poor showing of Haswell could indicate the workload is not well-suited to its architecture, or that the compilers/optimizations used were not effectively targeting its specific features.
* **Practical Implication:** For developers seeking maximum performance on these platforms for this type of workload, investing in low-level optimization (Assembly or ISPC) appears justified, especially on KNC hardware. The relatively similar performance of `icc` and `OpenMP 4` suggests that simply enabling OpenMP parallelization without further tuning may not yield benefits over the base compiler for this specific task.
**Language Declaration:** All text in the image is in English.