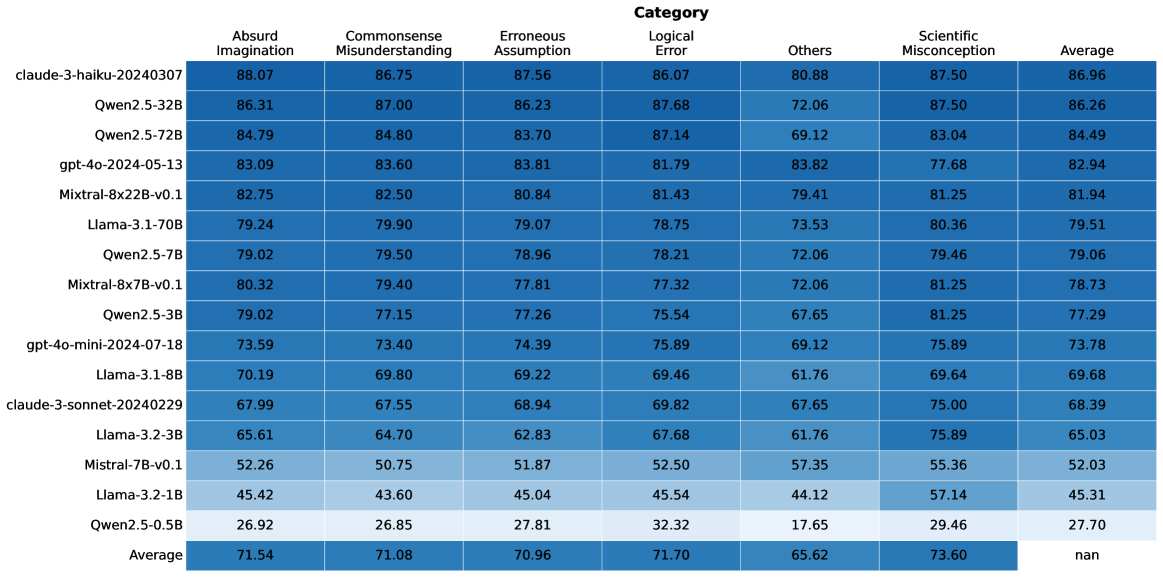
## Heatmap: Model Performance Across Error Categories
### Overview
This heatmap displays the performance of various language models across six different categories of errors: Absurd Imagination, Commonsense Misunderstanding, Erroneous Assumption, Logical Error, Others, and Scientific Misconception. Performance is measured as a percentage, and an "Average" score is provided for each model. The heatmap uses a color gradient to represent performance, with darker shades indicating higher scores.
### Components/Axes
* **Rows:** Represent different language models (claude-3-haiku-20240307, Qwen2.5-32B, Qwen2.5-72B, gpt-4o-2024-05-13, Mixtral-8x22B-v0.1, Llama-3-1-70B, Qwen2.5-7B, Mixtral-8x7B-v0.1, Qwen2.5-3B, gpt-4o-mini-2024-07-18, Llama-3-1-8B, claude-3-sonnet-20240229, Llama-7B-v2, Llama-2-70B, Llama-13B-v2, Qwen1.5-110B).
* **Columns:** Represent error categories: Absurd Imagination, Commonsense Misunderstanding, Erroneous Assumption, Logical Error, Others, Scientific Misconception, and Average.
* **Color Scale:** A gradient from light to dark, where darker shades represent higher percentage values.
* **Legend:** Not explicitly present, but the color gradient serves as an implicit legend.
### Detailed Analysis
Here's a breakdown of the data, row by row, with approximate values and trend observations. I will state the model, then the values for each category in order: Absurd Imagination, Commonsense Misunderstanding, Erroneous Assumption, Logical Error, Others, Scientific Misconception, Average.
1. **claude-3-haiku-20240307:** 88.07, 86.75, 87.56, 86.07, 80.88, 87.50, 86.96
2. **Qwen2.5-32B:** 86.31, 87.00, 86.23, 87.68, 72.06, 87.50, 86.26
3. **Qwen2.5-72B:** 84.79, 84.80, 83.70, 87.14, 69.12, 83.04, 84.49
4. **gpt-4o-2024-05-13:** 83.09, 83.60, 83.81, 81.79, 83.82, 77.68, 82.94
5. **Mixtral-8x22B-v0.1:** 82.75, 82.50, 80.84, 81.43, 79.41, 81.25, 81.94
6. **Llama-3-1-70B:** 79.24, 79.90, 79.07, 78.75, 73.53, 80.36, 79.51
7. **Qwen2.5-7B:** 79.02, 79.50, 78.96, 78.21, 72.06, 79.46, 79.06
8. **Mixtral-8x7B-v0.1:** 80.32, 79.40, 77.81, 77.32, 72.06, 81.25, 78.73
9. **Qwen2.5-3B:** 79.02, 77.15, 77.26, 75.54, 67.65, 81.25, 77.29
10. **gpt-4o-mini-2024-07-18:** 73.59, 73.40, 74.39, 75.89, 69.12, 75.89, 73.78
11. **Llama-3-1-8B:** 70.19, 69.80, 69.22, 69.46, 61.76, 69.64, 69.68
12. **claude-3-sonnet-20240229:** 67.99, 67.55, 68.94, 69.82, 67.65, 75.00, 68.39
13. **Llama-7B-v2:** 65.61, 65.75, 61.87, 63.56, 64.12, 68.89, 65.03
14. **Llama-2-70B:** 59.24, 59.40, 58.03, 57.35, 42.44, 62.50, 58.31
15. **Llama-13B-v2:** 45.22, 43.60, 45.04, 47.54, 41.52, 56.74, 46.31
16. **Qwen1.5-110B:** 42.96, 42.85, 43.21, 46.82, 42.44, 59.00, 47.06
17. **Llama-34B-v2:** 41.54, 41.20, 40.96, 43.52, 40.88, 53.26, 42.85
**Trends:**
* **claude-3-haiku-20240307** consistently performs the highest across most categories.
* **Qwen2.5-32B** and **Qwen2.5-72B** also show strong performance, generally above 80% in most categories.
* The Llama models (especially the smaller ones like Llama-7B-v2, Llama-13B-v2, and Llama-34B-v2) generally exhibit lower performance, particularly in categories like Commonsense Misunderstanding and Erroneous Assumption.
* Performance generally decreases as the model size decreases (within the Llama family).
### Key Observations
* The largest performance differences are observed in the "Others" and "Commonsense Misunderstanding" categories.
* The models demonstrate a relatively consistent performance profile across the error categories, with some models consistently outperforming others.
* There is a clear trade-off between model size and performance, with larger models generally achieving higher scores.
* The "Absurd Imagination" category consistently has the highest scores, suggesting that models are generally good at avoiding nonsensical outputs.
### Interpretation
This heatmap provides a comparative analysis of language model performance across different types of errors. The data suggests that models like claude-3-haiku-20240307, Qwen2.5-32B, and Qwen2.5-72B are more robust and less prone to making errors in various scenarios. The lower scores in the "Others" category indicate that these models struggle with errors that don't fall into well-defined categories, potentially highlighting areas where further improvement is needed.
The consistent trend of larger models performing better suggests that model capacity plays a crucial role in error reduction. However, it's important to note that model size is not the only factor, as different architectures and training data can also influence performance.
The heatmap also reveals that models are generally better at avoiding absurd outputs than at understanding commonsense or identifying erroneous assumptions. This suggests that current training methods may be more effective at preventing nonsensical responses than at ensuring logical reasoning and factual accuracy.
The data can be used to inform model selection and development efforts, guiding researchers and practitioners towards models that are best suited for specific tasks and applications. Further investigation into the "Others" category could reveal valuable insights into the types of errors that are most challenging for language models to overcome.