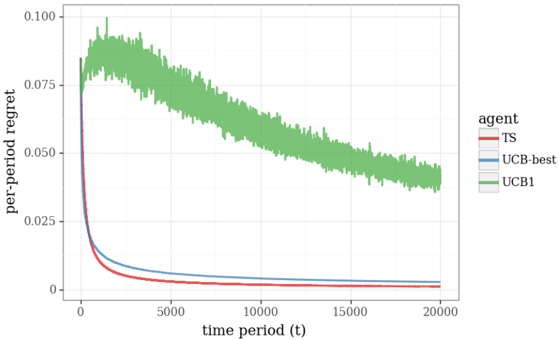
## Chart: Per-Period Regret vs. Time Period for Different Agents
### Overview
The image is a line chart comparing the per-period regret of three different agents (TS, UCB-best, and UCB1) over a time period of 20,000 units. The chart displays how the regret changes over time for each agent.
### Components/Axes
* **X-axis:** "time period (t)". Scale ranges from 0 to 20000, with tick marks at 0, 5000, 10000, 15000, and 20000.
* **Y-axis:** "per-period regret". Scale ranges from 0 to 0.100, with tick marks at 0, 0.025, 0.050, 0.075, and 0.100.
* **Legend (located on the right side of the chart):**
* Red line: TS (Thompson Sampling)
* Blue line: UCB-best (Upper Confidence Bound - best)
* Green line: UCB1 (Upper Confidence Bound 1)
### Detailed Analysis
* **TS (Red Line):** The per-period regret starts at approximately 0.075 and rapidly decreases to approximately 0.002 by time period 5000. It then remains relatively constant at around 0.002 for the rest of the time period.
* **UCB-best (Blue Line):** The per-period regret starts at approximately 0.075 and decreases to approximately 0.005 by time period 5000. It then remains relatively constant at around 0.005 for the rest of the time period.
* **UCB1 (Green Line):** The per-period regret starts at approximately 0.075, increases to approximately 0.095 around time period 2500, and then gradually decreases to approximately 0.040 by time period 20000. The line exhibits significant fluctuations throughout the entire time period.
### Key Observations
* TS and UCB-best perform significantly better than UCB1 in terms of per-period regret.
* TS has the lowest per-period regret after the initial time period.
* UCB1 has a higher initial regret and exhibits more fluctuation than the other two agents.
### Interpretation
The chart demonstrates the performance of three different reinforcement learning agents in terms of per-period regret over time. The results suggest that Thompson Sampling (TS) and UCB-best are more effective at minimizing regret compared to UCB1 in this particular scenario. The initial exploration phase seems to have a higher regret for all agents, but TS and UCB-best quickly converge to a low regret value, while UCB1's regret remains significantly higher and more volatile. This could be due to the exploration-exploitation trade-off handled differently by each algorithm. TS and UCB-best likely exploit better actions more quickly, while UCB1 might continue to explore less promising actions for a longer period.