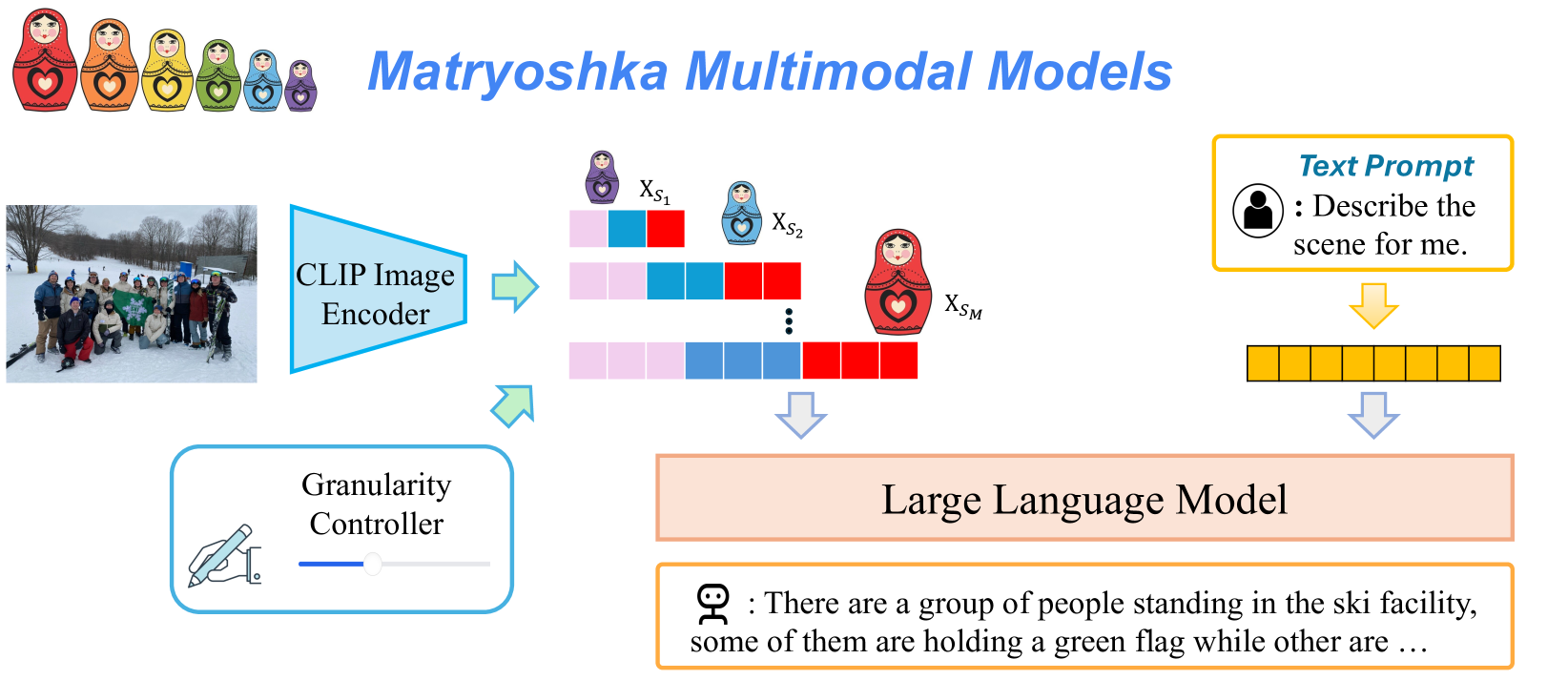
## Diagram: Matryoshka Multimodal Models
### Overview
The image illustrates a system called "Matryoshka Multimodal Models" that processes both image and text inputs to generate a descriptive text output. The system uses a CLIP Image Encoder, a Granularity Controller, and a Large Language Model. The image input is a photograph of a group of people in a snowy environment. The text input is a prompt asking for a description of the scene.
### Components/Axes
* **Title:** Matryoshka Multimodal Models
* **Input Image:** A photograph of a group of people standing in a snowy landscape.
* **CLIP Image Encoder:** A light blue trapezoid labeled "CLIP Image Encoder". It processes the input image.
* **Image Encoding:** The output of the CLIP Image Encoder is represented by a series of colored blocks, with three examples shown, labeled X<sub>S1</sub>, X<sub>S2</sub>, and X<sub>SM</sub>. Each example consists of a sequence of blocks colored pink, light blue, and red. The proportion of red blocks increases from X<sub>S1</sub> to X<sub>SM</sub>.
* **Granularity Controller:** A rounded rectangle labeled "Granularity Controller" with a slider. The slider is positioned approximately 75% to the right.
* **Large Language Model:** A light orange rectangle labeled "Large Language Model".
* **Text Prompt:** A yellow rounded rectangle labeled "Text Prompt" containing a user icon and the text ": Describe the scene for me."
* **Text Encoding:** The output of the Text Prompt is represented by a series of yellow blocks.
* **Output Text:** A light orange rounded rectangle containing a robot icon and the text ": There are a group of people standing in the ski facility, some of them are holding a green flag while other are..."
* **Matryoshka Dolls:** A row of six Matryoshka dolls of varying sizes and colors are displayed at the top-left of the image.
### Detailed Analysis
1. **Image Input:** The photograph shows a group of approximately 15 people standing in a snowy environment. Some are holding a green flag.
2. **CLIP Image Encoder:** The CLIP Image Encoder processes the image and generates a series of encoded representations.
3. **Image Encoding (X<sub>S1</sub>, X<sub>S2</sub>, X<sub>SM</sub>):**
* X<sub>S1</sub>: Contains 5 pink blocks, 1 light blue block, and 2 red blocks.
* X<sub>S2</sub>: Contains 3 pink blocks, 2 light blue blocks, and 3 red blocks.
* X<sub>SM</sub>: Contains 1 pink block, 2 light blue blocks, and 5 red blocks.
4. **Granularity Controller:** The slider is positioned towards the right, suggesting a higher level of granularity.
5. **Text Prompt:** The text prompt asks the system to describe the scene.
6. **Output Text:** The output text describes the scene, mentioning a group of people in a ski facility and a green flag.
### Key Observations
* The proportion of red blocks in the image encoding increases from X<sub>S1</sub> to X<sub>SM</sub>, potentially representing different levels of detail or focus within the image.
* The Granularity Controller influences the level of detail in the image encoding.
* The Large Language Model combines the image and text encodings to generate a descriptive text output.
### Interpretation
The diagram illustrates a multimodal system that combines image and text inputs to generate a descriptive text output. The CLIP Image Encoder processes the image, and the Granularity Controller adjusts the level of detail in the image encoding. The Large Language Model then combines the image and text encodings to generate a descriptive text output. The Matryoshka dolls in the title likely symbolize the hierarchical or nested nature of the image encoding process, where different levels of detail are captured and processed. The increasing proportion of red blocks in the image encoding might represent a focus on specific objects or regions within the image as the granularity increases.