# Technical Document Extraction: Matryoshka Multimodal Models
## 1. Header Information
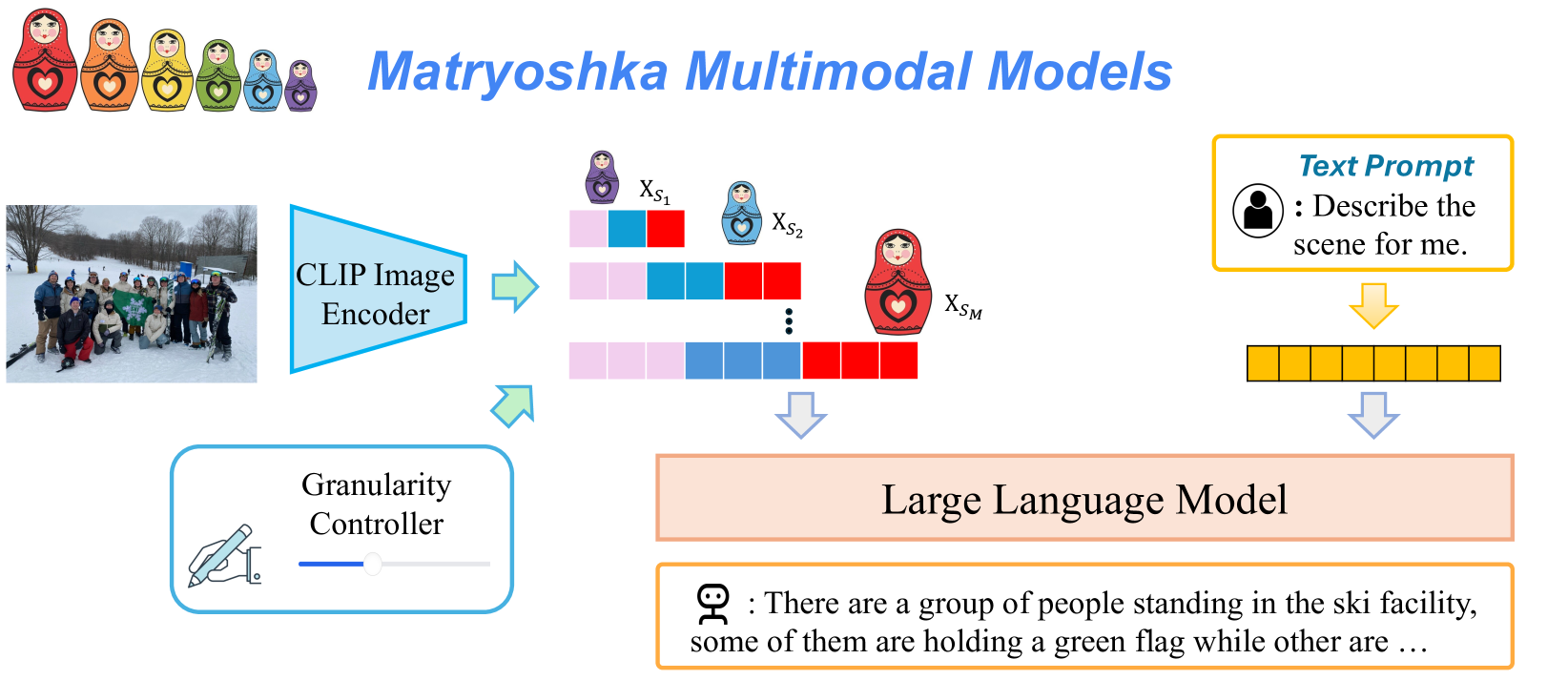
* **Title:** Matryoshka Multimodal Models (displayed in blue, italicized sans-serif font).
* **Visual Motif:** A sequence of six Matryoshka (nesting) dolls of decreasing size, colored red, orange, yellow, green, light blue, and purple.
## 2. Component Analysis and Workflow
The diagram illustrates a multimodal architecture where image and text inputs are processed through a Large Language Model (LLM) with adjustable visual granularity.
### A. Image Input and Encoding
* **Input Image:** A photograph of a group of people posing in a snowy outdoor setting (ski facility), some holding a green flag.
* **Encoder:** The image is fed into a **CLIP Image Encoder** (represented by a light blue trapezoid).
* **Granularity Controller:** A UI-style box containing a hand-drawing icon and a slider bar. An arrow points from this controller toward the encoding process, indicating it influences the output of the visual features.
### B. Matryoshka Visual Embeddings (Main Feature)
The output of the encoder is represented as nested sets of visual tokens (blocks), corresponding to different scales of the Matryoshka dolls:
* **Smallest Scale ($X_{S_1}$):** Represented by the smallest purple doll. It consists of 3 blocks (Pink, Blue, Red).
* **Medium Scale ($X_{S_2}$):** Represented by a light blue doll. It consists of 6 blocks (2 Pink, 2 Blue, 2 Red).
* **Largest Scale ($X_{S_M}$):** Represented by the largest red doll. It consists of a longer sequence of blocks (4 Pink, 4 Blue, 4 Red).
* **Vertical Ellipsis:** Indicates intermediate scales between $X_{S_2}$ and $X_{S_M}$.
* **Flow:** These multi-scale embeddings are aggregated and directed downward into the Large Language Model.
### C. Text Input
* **Text Prompt Box:** A yellow-bordered box containing a user icon.
* **Transcribed Text:** "Text Prompt [User Icon]: Describe the scene for me."
* **Tokenization:** The text prompt is converted into a sequence of 10 yellow blocks (tokens) before entering the LLM.
### D. Processing and Output
* **Central Processor:** A light orange rectangular block labeled **Large Language Model**.
* **Output Box:** A yellow-bordered box containing a robot icon.
* **Transcribed Output:** "[Robot Icon]: There are a group of people standing in the ski facility, some of them are holding a green flag while other are ..."
## 3. Summary of Logical Flow
1. An **Image** is processed by a **CLIP Image Encoder**.
2. A **Granularity Controller** determines the level of detail extracted.
3. The visual data is structured into **Matryoshka Embeddings** ($X_{S_1}$ to $X_{S_M}$), where smaller sets are nested within larger, more detailed sets.
4. A **Text Prompt** is tokenized.
5. Both the **Visual Embeddings** and **Text Tokens** are fed into the **Large Language Model**.
6. The LLM generates a descriptive **Text Output** based on the provided visual granularity and prompt.