\n
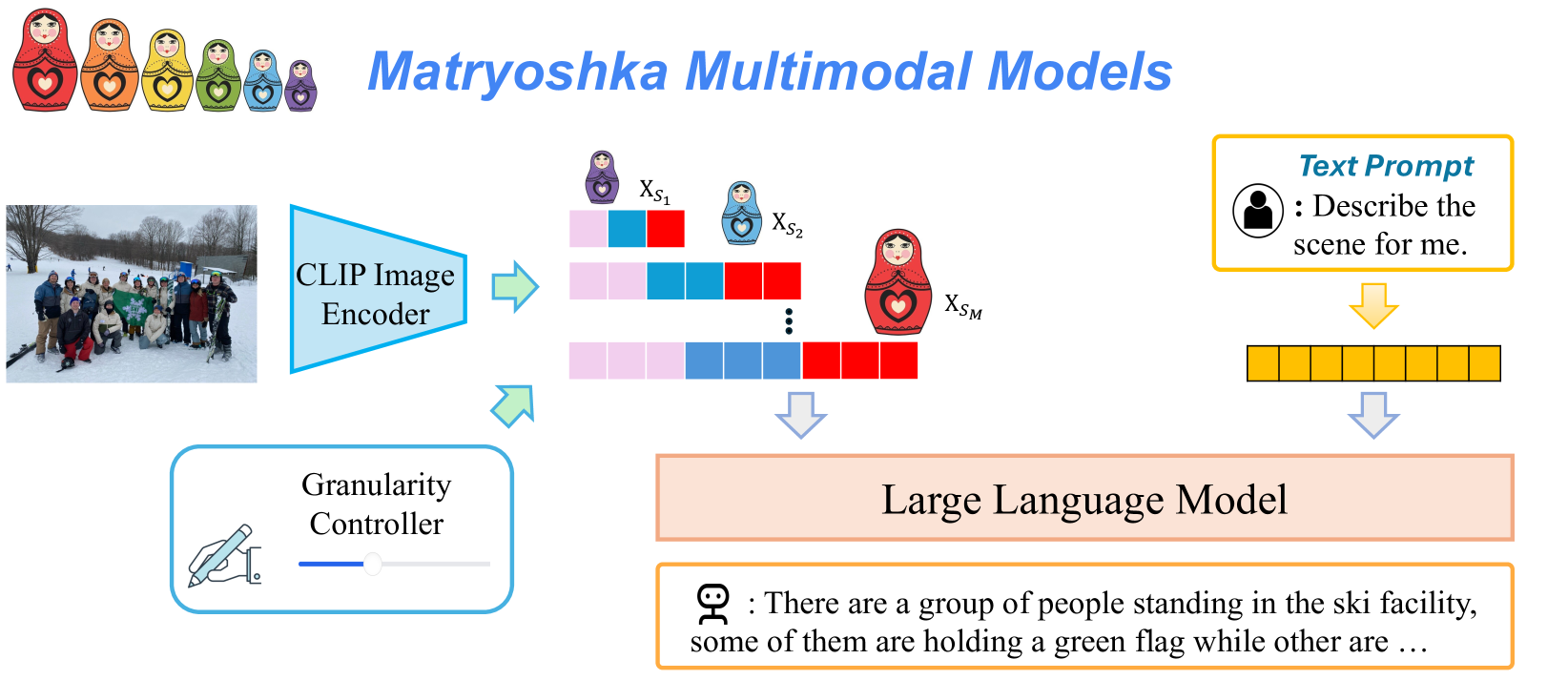
## Diagram: Matryoshka Multimodal Models
### Overview
This diagram illustrates the architecture of "Matryoshka Multimodal Models," a system that combines image and text processing using a CLIP Image Encoder, a Granularity Controller, and a Large Language Model. The diagram depicts the flow of information from an input image and text prompt through these components to generate a textual description.
### Components/Axes
The diagram consists of the following components:
* **Header:** "Matryoshka Multimodal Models" in teal text.
* **Image Input:** A photograph of a group of people in a snowy outdoor scene, likely a ski facility.
* **CLIP Image Encoder:** A blue rounded rectangle labeled "CLIP Image Encoder."
* **Granularity Controller:** A blue rounded rectangle labeled "Granularity Controller."
* **Text Prompt:** A light-yellow rounded rectangle with a speech bubble icon and the text "Describe the scene for me."
* **Intermediate Representations (Xs):** A series of colored rectangles (red, blue, and pink) representing intermediate image representations labeled X<sub>S1</sub>, X<sub>S2</sub>, ..., X<sub>SM</sub>.
* **Large Language Model:** A large, light-yellow rounded rectangle labeled "Large Language Model."
* **Output Text:** A speech bubble icon with the text "There are a group of people standing in the ski facility, some of them holding a green flag while other are..."
### Detailed Analysis or Content Details
The diagram shows the following flow:
1. **Image Input:** An image of people in a snowy scene is fed into the CLIP Image Encoder.
2. **CLIP Image Encoder:** The CLIP Image Encoder processes the image and generates a series of intermediate representations, denoted as X<sub>S1</sub> through X<sub>SM</sub>. Each X<sub>S</sub> is represented by a colored rectangle with a varying pattern of red and blue blocks. The number of intermediate representations (M) is not explicitly specified but is indicated by the ellipsis (...).
3. **Granularity Controller:** The output of the CLIP Image Encoder is then passed to the Granularity Controller. The diagram shows an arrow connecting the intermediate representations to the Granularity Controller.
4. **Text Prompt:** A text prompt, "Describe the scene for me," is also provided as input.
5. **Large Language Model:** Both the output from the Granularity Controller and the text prompt are fed into the Large Language Model.
6. **Output Text:** The Large Language Model generates a textual description of the scene: "There are a group of people standing in the ski facility, some of them holding a green flag while other are..."
The intermediate representations (X<sub>S1</sub> to X<sub>SM</sub>) are visually distinct, with varying arrangements of red and blue blocks within each rectangle. This suggests that the CLIP Image Encoder generates different levels of abstraction or granularity of the image.
### Key Observations
* The diagram emphasizes the multi-stage processing of the image, from initial encoding to controlled granularity and final text generation.
* The use of colored rectangles to represent intermediate representations suggests that these representations are multi-dimensional or have multiple features.
* The Granularity Controller appears to play a crucial role in modulating the information flow between the image encoder and the language model.
* The output text is a partial sentence, indicating that the language model can generate more extensive descriptions.
### Interpretation
The diagram illustrates a multimodal model that leverages the strengths of both image and text processing. The CLIP Image Encoder extracts visual features from the image, while the Large Language Model generates natural language descriptions. The Granularity Controller likely allows for controlling the level of detail or abstraction in the generated descriptions. The "Matryoshka" metaphor (referencing Russian nesting dolls, depicted at the top of the diagram) suggests that the model processes information at multiple levels of granularity, similar to how Matryoshka dolls contain smaller dolls within them.
The system aims to bridge the gap between visual and textual information, enabling machines to "understand" and describe images in a human-like manner. The diagram highlights the importance of intermediate representations and the ability to control the granularity of these representations for effective multimodal processing. The partial output text suggests the model is capable of generating coherent and contextually relevant descriptions.