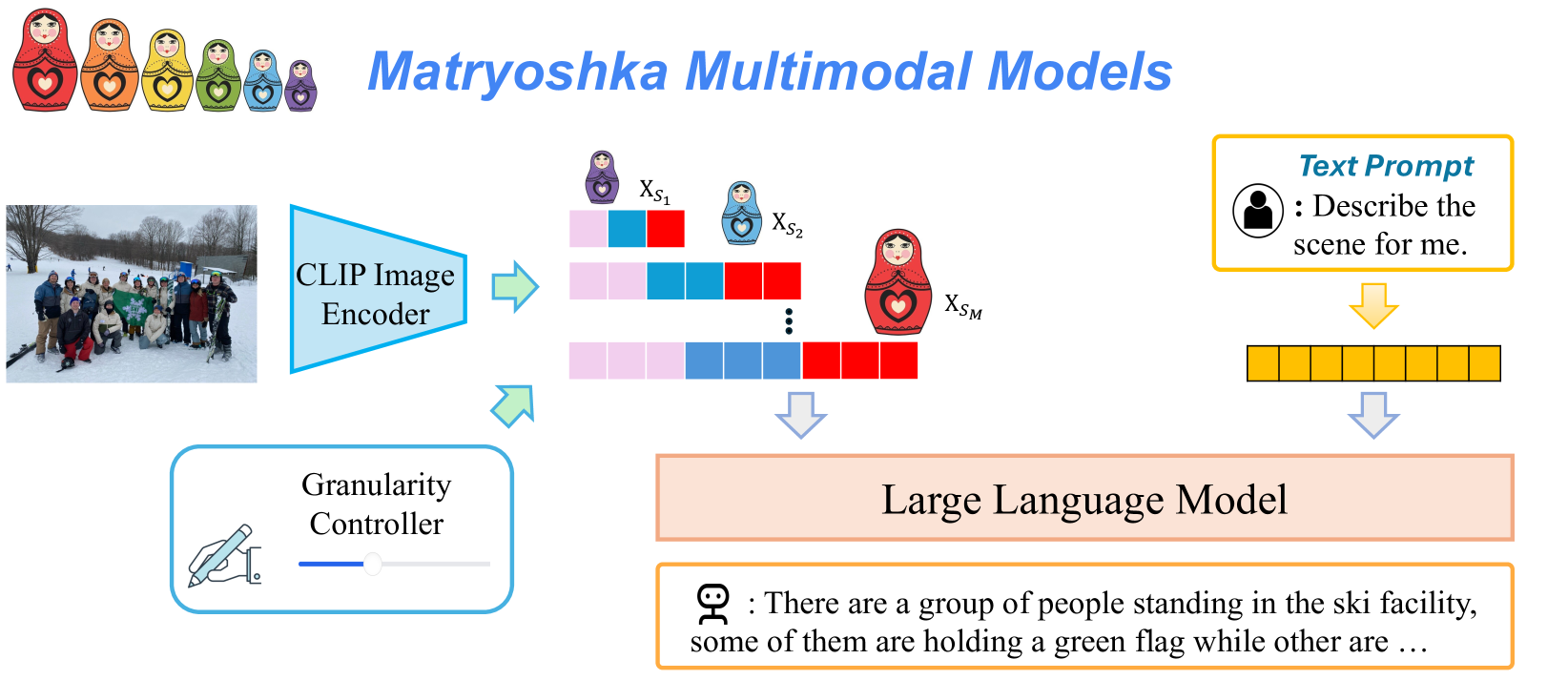
## Diagram: Matryoshka Multimodal Models Architecture
### Overview
This image is a technical diagram illustrating the architecture of a "Matryoshka Multimodal Model." The system processes an input image and a text prompt to generate a textual description. The core concept, symbolized by Russian nesting dolls (matryoshka), is that the image representation can be encoded at multiple, nested levels of granularity, which are then processed by a Large Language Model (LLM) alongside the text prompt.
### Components/Axes
The diagram is organized into a flow from left to right, with distinct input, processing, and output stages.
**1. Input Stage (Left Side):**
* **Image Input:** A photograph showing a group of people posing in a snowy, outdoor ski facility. Some individuals are holding a green flag.
* **Text Prompt Input:** A yellow-bordered box containing:
* **Label:** `Text Prompt`
* **Icon:** A user silhouette.
* **Prompt Text:** `: Describe the scene for me.`
**2. Processing Stage (Center):**
* **CLIP Image Encoder:** A blue trapezoidal block that receives the input image. An arrow points from it to the multi-granularity representations.
* **Granularity Controller:** A blue-bordered box below the encoder, containing:
* **Label:** `Granularity Controller`
* **Icon:** A hand adjusting a slider.
* **Function:** This component controls the level of detail (granularity) extracted from the image by the encoder.
* **Multi-Granularity Image Representations:** The output of the CLIP Image Encoder is depicted as multiple rows of colored blocks (pink, blue, red), each associated with a matryoshka doll icon of decreasing size. These are labeled:
* `X_S₁` (smallest doll, top row)
* `X_S₂` (medium doll, middle row)
* `⋮` (vertical ellipsis indicating continuation)
* `X_Sₘ` (largest doll, bottom row)
* This visually represents a set of image embeddings at different scales or levels of abstraction (`S₁` to `Sₘ`).
* **Text Encoder (Implied):** The text prompt is processed into a sequence of yellow blocks, representing its tokenized or embedded form.
**3. Integration & Output Stage (Right Side):**
* **Large Language Model (LLM):** A large, peach-colored rectangular block. It receives two inputs:
1. The multi-granularity image representations (indicated by a downward arrow from the `X_S` blocks).
2. The encoded text prompt (indicated by a downward arrow from the yellow blocks).
* **Generated Output:** An orange-bordered box containing the model's response:
* **Icon:** A robot head.
* **Output Text:** `: There are a group of people standing in the ski facility, some of them are holding a green flag while other are ...` (The text ends with an ellipsis, indicating continuation).
**4. Title & Symbolism:**
* **Title:** `Matryoshka Multimodal Models` in large, blue, italicized font at the top center.
* **Symbolic Header:** A row of seven colorful matryoshka dolls (red, orange, yellow, green, light blue, dark blue, purple) in the top-left corner, reinforcing the "nested" or hierarchical model concept.
### Detailed Analysis
The diagram details a specific multimodal AI pipeline:
1. **Image Encoding:** An image is passed through a CLIP Image Encoder.
2. **Granular Control:** A "Granularity Controller" modulates the encoder to produce not one, but a series of image representations (`X_S₁` through `X_Sₘ`). Each representation corresponds to a different level of detail, metaphorically shown as nested dolls where `X_S₁` is the most compact (coarse) and `X_Sₘ` is the most detailed (fine).
3. **Text Encoding:** A user's text prompt is separately encoded.
4. **Multimodal Fusion:** The set of image representations and the text encoding are fed into a Large Language Model.
5. **Text Generation:** The LLM synthesizes this information to generate a natural language description of the image, as shown in the sample output.
### Key Observations
* **Hierarchical Representation:** The core innovation highlighted is the generation of multiple, scale-aware image features (`X_S₁...X_Sₘ`) instead of a single fixed representation.
* **Explicit Control:** The "Granularity Controller" is a distinct, user-adjustable component, suggesting the model's output detail can be tuned.
* **CLIP-Based:** The image encoder is specified as "CLIP," indicating the use of a contrastive language-image pre-training foundation.
* **Flow Clarity:** The data flow is clearly marked with arrows: image → encoder → multi-scale features → LLM, and text prompt → encoder → LLM.
* **Sample Output:** The generated text directly references elements from the input image ("group of people," "ski facility," "green flag"), demonstrating the model's function.
### Interpretation
This diagram proposes an architecture for more flexible and controllable multimodal understanding. The "Matryoshka" concept implies that the model can operate at different levels of visual abstraction, potentially allowing for:
* **Efficiency:** Using coarser representations (`X_S₁`) for quick, high-level understanding.
* **Detail:** Leveraging finer representations (`X_Sₘ`) for generating rich, detailed descriptions.
* **Adaptability:** The Granularity Controller could allow a user or system to dynamically trade off between speed/computational cost and descriptive detail.
The architecture suggests a move beyond single-vector image embeddings towards a more nuanced, multi-scale visual understanding that is then interpreted by a powerful LLM. The sample output confirms the system's purpose: to generate descriptive text that accurately reflects the content of an input image, guided by a user's prompt. The ellipsis in the output text implies the model generates a complete, ongoing description.