## Matryoshka Multimodal Models
### Overview
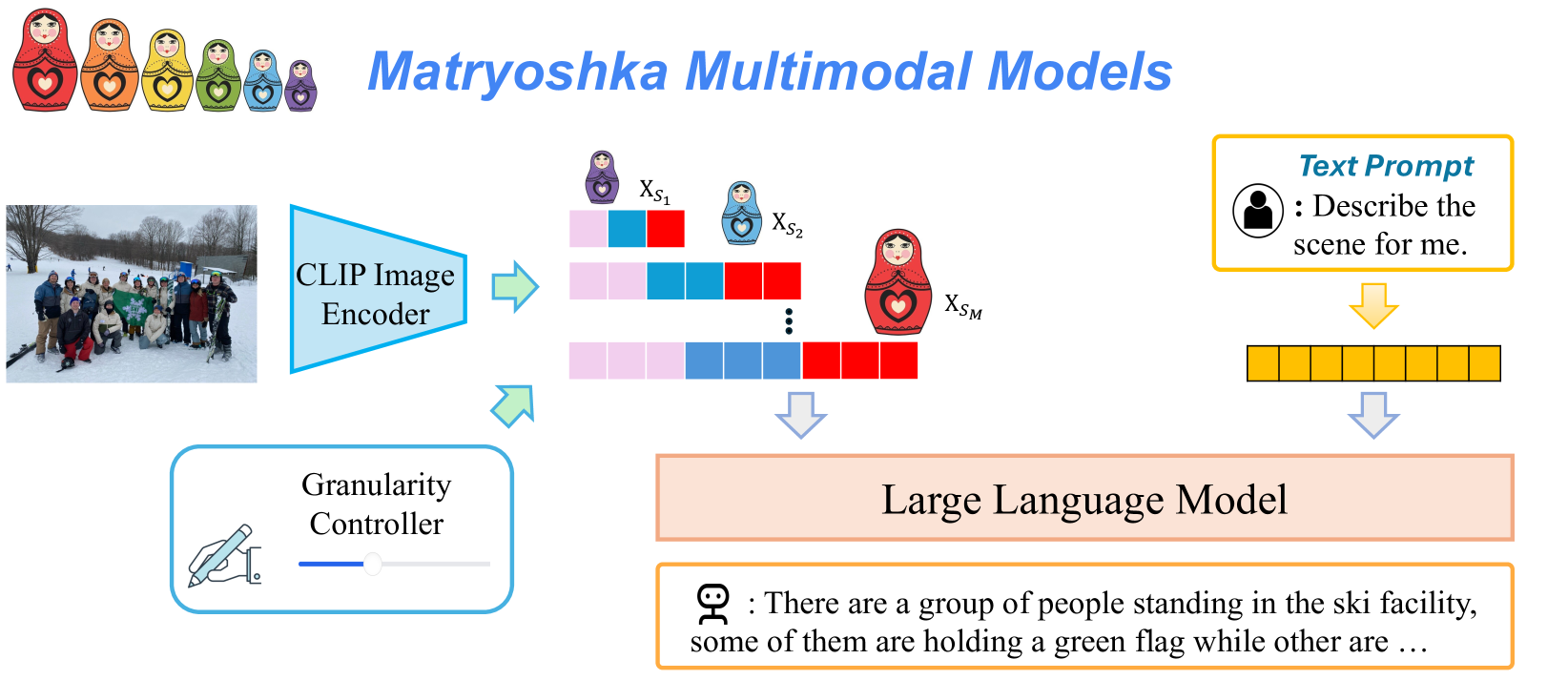
The image is a flowchart illustrating the process of using Matryoshka multimodal models for image and text processing. It shows how an image is encoded by a CLIP image encoder, then processed by a large language model to generate a text description.
### Components/Axes
- **CLIP Image Encoder**: A blue box with an arrow pointing to the left, indicating the input of an image.
- **Matryoshka Models**: A series of nested dolls, each representing a different level of granularity in the image processing.
- **Large Language Model**: A pink box with an arrow pointing to the right, indicating the output of the image processing.
- **Text Prompt**: A yellow box with a prompt asking to describe the scene for the model.
- **Granularity Controller**: A blue box with a slider, indicating the level of detail in the image processing.
### Detailed Analysis or ### Content Details
- The image is processed through the CLIP image encoder, which converts the image into a numerical representation.
- The numerical representation is then processed by the Matryoshka models, which are designed to handle different levels of granularity in the image.
- The processed data is then fed into the large language model, which generates a text description of the scene.
- The granularity controller allows for adjusting the level of detail in the image processing, with the slider indicating the current level of granularity.
### Key Observations
- The image processing is done in a hierarchical manner, with each level of granularity processing the previous level.
- The large language model is able to generate a text description of the scene, even when the image is processed at a low level of granularity.
- The granularity controller allows for fine-tuning the level of detail in the image processing, which can affect the quality of the text description.
### Interpretation
The Matryoshka multimodal models are designed to handle complex scenes by processing them at different levels of granularity. The CLIP image encoder converts the image into a numerical representation, which is then processed by the Matryoshka models to generate a text description. The granularity controller allows for adjusting the level of detail in the image processing, which can affect the quality of the text description. The large language model is able to generate a text description of the scene, even when the image is processed at a low level of granularity. This suggests that the Matryoshka multimodal models are capable of handling complex scenes and generating accurate text descriptions.