# Technical Document Extraction: Matryoshka Multimodal Models
## Diagram Overview
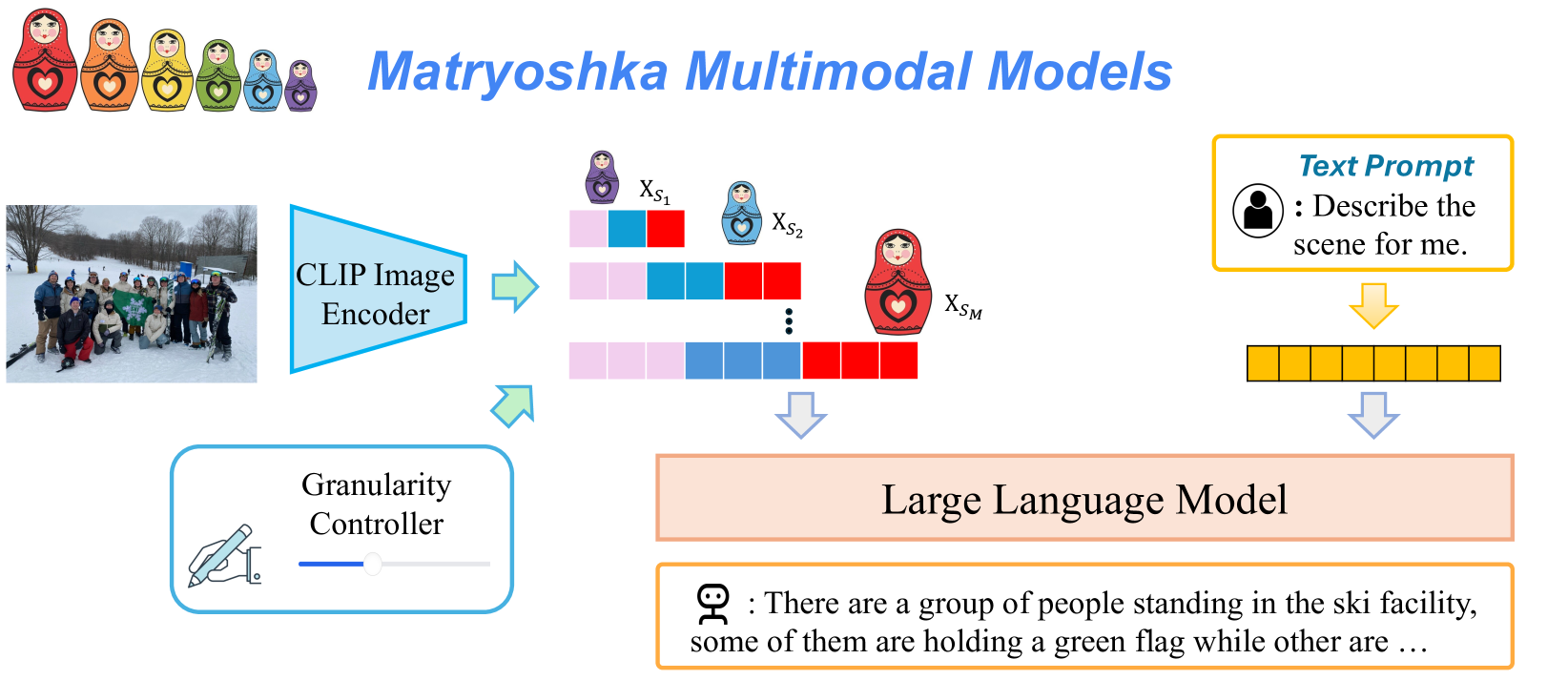
The image depicts a **multimodal model architecture** titled **"Matryoshka Multimodal Models"**, using Russian nesting dolls (Matryoshka) as visual metaphors for hierarchical model components. The diagram illustrates the flow of data from input image to text generation, with explicit control over granularity.
---
## Key Components and Flow
### 1. Input Image
- **Description**: A photograph of a group of people in a snowy environment, holding a green flag.
- **Position**: Bottom-left quadrant of the diagram.
### 2. CLIP Image Encoder
- **Function**: Processes the input image into a latent representation.
- **Output**: A sequence of feature vectors labeled `X_S1` to `X_SM`, where:
- `X_S1`: Smallest model (purple doll).
- `X_SM`: Largest model (red doll).
- **Visualization**: Color-coded bars (purple → red) representing increasing model size.
### 3. Granularity Controller
- **Function**: Adjusts the level of detail in the output text.
- **Interface**: A slider (blue line) with a knob, positioned below the encoder.
- **Effect**: Modulates the input to the Large Language Model (LLM).
### 4. Large Language Model (LLM)
- **Function**: Generates descriptive text based on the processed image and granularity settings.
- **Input**: Feature vectors from the encoder and granularity control signal.
- **Output**: Partial sentence:
`"There are a group of people standing in the ski facility, some of them are holding a green flag while other are ..."`
### 5. Text Prompt Interface
- **Description**: A yellow box with a person icon and the instruction:
`"Describe the scene for me."`
- **Position**: Top-right quadrant of the diagram.
---
## Color Coding and Model Sizes
- **Nesting Dolls**: Represent model sizes, with colors corresponding to:
- **Red**: Largest model (`X_SM`).
- **Orange**: Second-largest.
- **Yellow**: Third-largest.
- **Green**: Fourth-largest.
- **Blue**: Fifth-largest.
- **Purple**: Smallest model (`X_S1`).
- **Bars**: Horizontal color blocks (purple → red) visualize the sequence of feature vectors.
---
## Spatial Grounding
- **Legend**: No explicit legend present. Color coding is inferred from doll labels and bar colors.
- **Flow Arrows**:
- Green arrows indicate data flow from the image to the encoder.
- Blue arrows indicate data flow from the encoder to the LLM.
- Yellow arrow connects the text prompt to the LLM input.
---
## Textual Elements
1. **Title**:
`"Matryoshka Multimodal Models"` (blue text, top-center).
2. **Text Prompt**:
`"Describe the scene for me."` (black text, yellow box).
3. **LLM Output**:
`"There are a group of people standing in the ski facility, some of them are holding a green flag while other are ..."` (black text, beige box).
---
## Diagram Structure
- **Header**: Title and nesting dolls.
- **Main Chart**:
- Left: Image and encoder.
- Center: Granularity controller and LLM.
- Right: Text prompt and output.
- **Footer**: No explicit footer.
---
## Notes
- **Language**: All text is in English except the title reference to "Matryoshka" (Russian for nesting dolls).
- **Missing Data**: No numerical values or quantitative trends present; the diagram is conceptual.
- **Assumptions**:
- The nesting dolls symbolize hierarchical model sizes.
- The Granularity Controller adjusts the LLM's output detail level.
---
## Conclusion
This diagram illustrates a **hierarchical multimodal system** where image features are processed through adjustable model sizes (Matryoshka-inspired) and controlled granularity to generate descriptive text. The system emphasizes modularity and scalability, with explicit user control over output detail.