## Diagram: Quantization Aware Training (QAT) and Post Training Quantization (PTQ)
### Overview
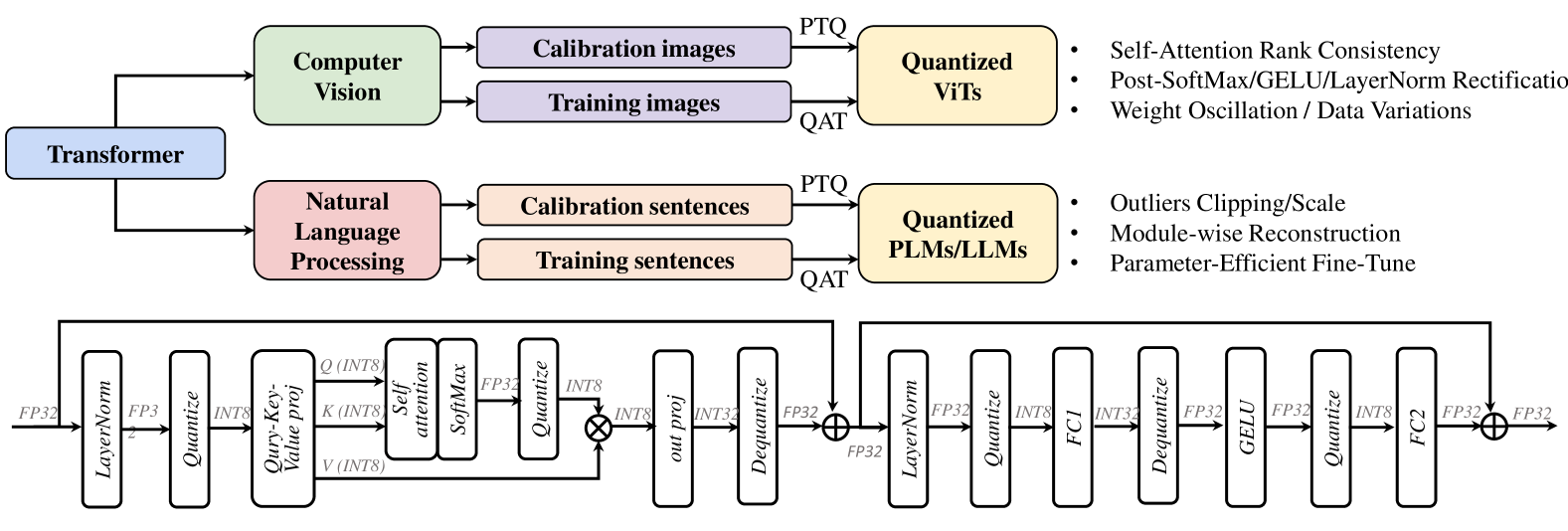
The image is a diagram illustrating the process of Quantization Aware Training (QAT) and Post Training Quantization (PTQ) applied to both Computer Vision and Natural Language Processing models, specifically Transformers. It shows the data flow and key steps involved in quantizing these models.
### Components/Axes
* **Top-Left:** "Transformer" (Blue box) - Represents the starting point of the process.
* **Top-Middle:**
* "Computer Vision" (Green box) - Indicates the application of the process to computer vision models.
* "Calibration images" (Purple box) - Input for PTQ.
* "Training images" (Purple box) - Input for QAT.
* **Top-Right:**
* "Quantized ViTs" (Yellow box) - Output of the quantization process for Vision Transformers.
* Bullet points listing benefits:
* Self-Attention Rank Consistency
* Post-SoftMax/GELU/LayerNorm Rectification
* Weight Oscillation / Data Variations
* **Middle-Left:**
* "Natural Language Processing" (Red box) - Indicates the application of the process to natural language processing models.
* "Calibration sentences" (Peach box) - Input for PTQ.
* "Training sentences" (Peach box) - Input for QAT.
* **Middle-Right:**
* "Quantized PLMs/LLMs" (Yellow box) - Output of the quantization process for Language Models.
* Bullet points listing benefits:
* Outliers Clipping/Scale
* Module-wise Reconstruction
* Parameter-Efficient Fine-Tune
* **Bottom:** Detailed diagram of a Transformer block, showing the flow of data through various layers and operations.
* **Data Types:** FP32, FP3, INT8, INT32
* **Layers/Operations:** LayerNorm, Quantize, Query-Key-Value proj, Self attention, SoftMax, out proj, Dequantize, FC1, GELU, FC2
### Detailed Analysis
**Top Section:**
* The "Transformer" block feeds into both "Computer Vision" and "Natural Language Processing" blocks.
* Both "Computer Vision" and "Natural Language Processing" blocks have two outputs: "Calibration images/sentences" and "Training images/sentences".
* "Calibration images/sentences" are used for Post Training Quantization (PTQ).
* "Training images/sentences" are used for Quantization Aware Training (QAT).
* The outputs of the quantization processes are "Quantized ViTs" and "Quantized PLMs/LLMs" respectively.
**Bottom Section (Transformer Block):**
The diagram shows a detailed view of a single transformer block. The data flow is as follows:
1. **Input:** FP32
2. **LayerNorm:** Normalizes the input. Output: FP32
3. **Quantize:** Converts the data to INT8.
4. **Query-Key-Value proj:** Projects the input into query, key, and value vectors. Input: Q(INT8), K(INT8), V(INT8)
5. **Self attention:** Computes the attention weights.
6. **SoftMax:** Applies the softmax function.
7. **Quantize:** Converts the data to INT8.
8. **out proj:** Projects the output. Output: INT8
9. **Dequantize:** Converts the data back to FP32.
10. **Addition:** Adds the original input (FP32) to the output of the attention mechanism (FP32).
11. **LayerNorm:** Normalizes the input. Output: FP32
12. **Quantize:** Converts the data to INT8.
13. **FC1:** Fully connected layer. Input: INT8, Output: INT32
14. **Dequantize:** Converts the data back to FP32.
15. **GELU:** Applies the GELU activation function. Output: FP32
16. **Quantize:** Converts the data to INT8.
17. **FC2:** Fully connected layer. Input: INT8, Output: FP32
18. **Addition:** Adds the original input (FP32) to the output of the FC2 layer (FP32).
19. **Output:** FP32
### Key Observations
* The diagram highlights the two main approaches to quantization: QAT and PTQ.
* It shows how these approaches are applied to both computer vision and natural language processing models.
* The detailed transformer block diagram provides insights into the specific operations and data types involved in the quantization process.
* The diagram emphasizes the importance of quantization for improving the efficiency and performance of deep learning models.
### Interpretation
The diagram illustrates a common workflow for quantizing transformer-based models in both computer vision and natural language processing. Quantization is a technique used to reduce the memory footprint and computational cost of deep learning models by representing the model's weights and activations with lower precision data types (e.g., INT8) instead of floating-point numbers (e.g., FP32).
The diagram differentiates between two main quantization approaches:
* **Post-Training Quantization (PTQ):** This approach quantizes the model after it has been fully trained. It typically involves using a small calibration dataset to determine the optimal quantization parameters.
* **Quantization-Aware Training (QAT):** This approach incorporates the quantization process into the training loop. This allows the model to adapt to the quantization constraints and maintain accuracy.
The diagram suggests that both PTQ and QAT can be used to quantize ViTs (Vision Transformers) and PLMs/LLMs (Pre-trained Language Models/Large Language Models). The bullet points next to the "Quantized ViTs" and "Quantized PLMs/LLMs" boxes highlight some of the benefits of quantization, such as improved self-attention rank consistency, better handling of outliers, and parameter-efficient fine-tuning.
The detailed transformer block diagram provides a more granular view of the quantization process. It shows how the data is quantized and dequantized at various stages of the transformer block, and how the different layers and operations are affected by quantization. The use of different data types (FP32, INT8, INT32) throughout the block highlights the importance of carefully managing the precision of the data to maintain accuracy.