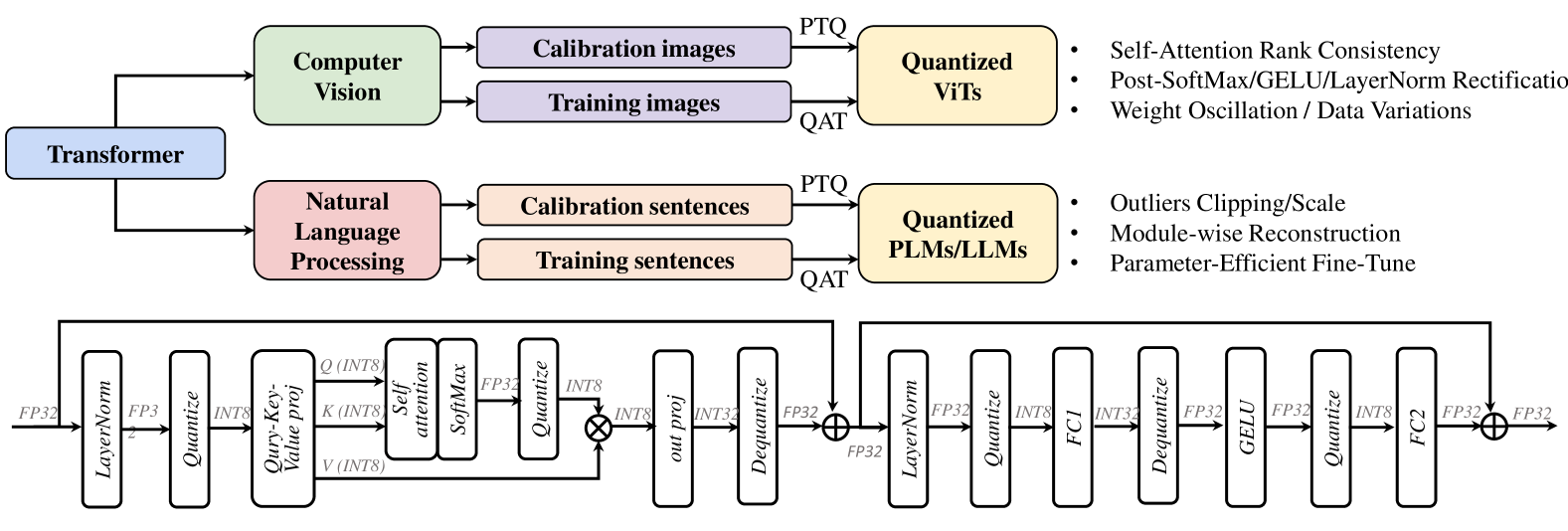
## Diagram: Transformer Quantization Pipeline
### Overview
This diagram illustrates a pipeline for quantizing Transformer models, specifically for both Computer Vision (ViTs) and Natural Language Processing (PLMs/LLMs). It shows the input data types, quantization methods, and resulting model types, along with techniques used to improve quantization performance. The diagram is structured with a top-level Transformer block branching into two parallel paths for Computer Vision and Natural Language Processing, each leading to quantized models. Below these paths are detailed block diagrams representing the quantization process within each domain.
### Components/Axes
The diagram consists of the following key components:
* **Transformer:** The overarching model architecture.
* **Computer Vision:** Branch dealing with image data.
* **Calibration images:** Input data for calibrating the quantization process.
* **Training images:** Input data for training the quantized model.
* **Quantized ViTs:** The output of the Computer Vision quantization pipeline.
* **Natural Language Processing:** Branch dealing with text data.
* **Calibration sentences:** Input data for calibrating the quantization process.
* **Training sentences:** Input data for training the quantized model.
* **Quantized PLMs/LLMs:** The output of the Natural Language Processing quantization pipeline.
* **Quantization Methods:**
* **PTQ (Post-Training Quantization):** A quantization method applied after training.
* **QAT (Quantization Aware Training):** A quantization method integrated into the training process.
* **Techniques for Quantized Models:** Lists of techniques to improve quantized model performance.
* **Detailed Quantization Blocks:** Represent the specific layers and operations involved in quantization for each domain. These blocks include layers like LayerNorm, Quantize, Self-Attention, GELU, and FC (Fully Connected).
* **Data Types:** FP32, INT8, INT32, INT3.
### Detailed Analysis or Content Details
The diagram can be broken down into three main sections: the high-level overview, the parallel processing paths, and the detailed quantization blocks.
**High-Level Overview:**
The "Transformer" block at the top-left feeds into two parallel branches: "Computer Vision" and "Natural Language Processing". Each branch receives different input data (images vs. sentences) and leads to a "Quantized" model type (ViTs vs. PLMs/LLMs).
**Parallel Processing Paths:**
* **Computer Vision:**
* Calibration images and training images are fed into the "Quantized ViTs" block via either PTQ or QAT.
* The right side of the "Quantized ViTs" block lists techniques: "Self-Attention Rank Consistency", "Post-SoftMax/GELU/LayerNorm Rectification", and "Weight Oscillation / Data Variations".
* **Natural Language Processing:**
* Calibration sentences and training sentences are fed into the "Quantized PLMs/LLMs" block via either PTQ or QAT.
* The right side of the "Quantized PLMs/LLMs" block lists techniques: "Outliers Clipping/Scale", "Module-wise Reconstruction", and "Parameter-Efficient Fine-Tune".
**Detailed Quantization Blocks:**
* **Computer Vision (Left Block):**
* FP32 -> LayerNorm -> Quantize -> Query-Key-Value proj (INT8) -> Self-Attention -> SoftMax -> Quantize (INT8) -> out proj (INT8) -> Dequantize -> INT32 -> FP32
* **Natural Language Processing (Right Block):**
* FP32 -> LayerNorm -> Quantize -> FC1 (INT8) -> Dequantize -> INT32 -> FP32 -> GELU -> Quantize -> FC2 (INT8) -> FP32
The arrows indicate the flow of data through the layers. The data type changes are explicitly shown (e.g., FP32 to INT8).
### Key Observations
* Both Computer Vision and Natural Language Processing branches utilize both PTQ and QAT for quantization.
* The detailed quantization blocks show a common pattern of FP32 -> Quantize -> INT8 -> Dequantize -> FP32, suggesting a mixed-precision quantization approach.
* The techniques listed for each domain are tailored to the specific challenges of each type of model.
* The diagram highlights the importance of calibration data for effective quantization.
* The use of INT8 quantization is prominent in both branches.
### Interpretation
This diagram demonstrates a comprehensive approach to quantizing Transformer models for both Computer Vision and Natural Language Processing. The use of both PTQ and QAT allows for flexibility in the quantization process, depending on the desired trade-off between accuracy and performance. The detailed quantization blocks reveal the specific layers and operations that are targeted for quantization, and the techniques listed suggest strategies for mitigating the accuracy loss that can occur during quantization. The diagram suggests that the goal is to reduce the model size and computational cost while maintaining acceptable accuracy. The distinction in techniques between the two branches indicates that the challenges of quantization differ between ViTs and PLMs/LLMs, requiring domain-specific optimization strategies. The inclusion of data type changes (FP32, INT8, INT32) highlights the mixed-precision approach, which aims to balance accuracy and efficiency.