## Flowchart: Hybrid Model Architecture for Computer Vision and Natural Language Processing
### Overview
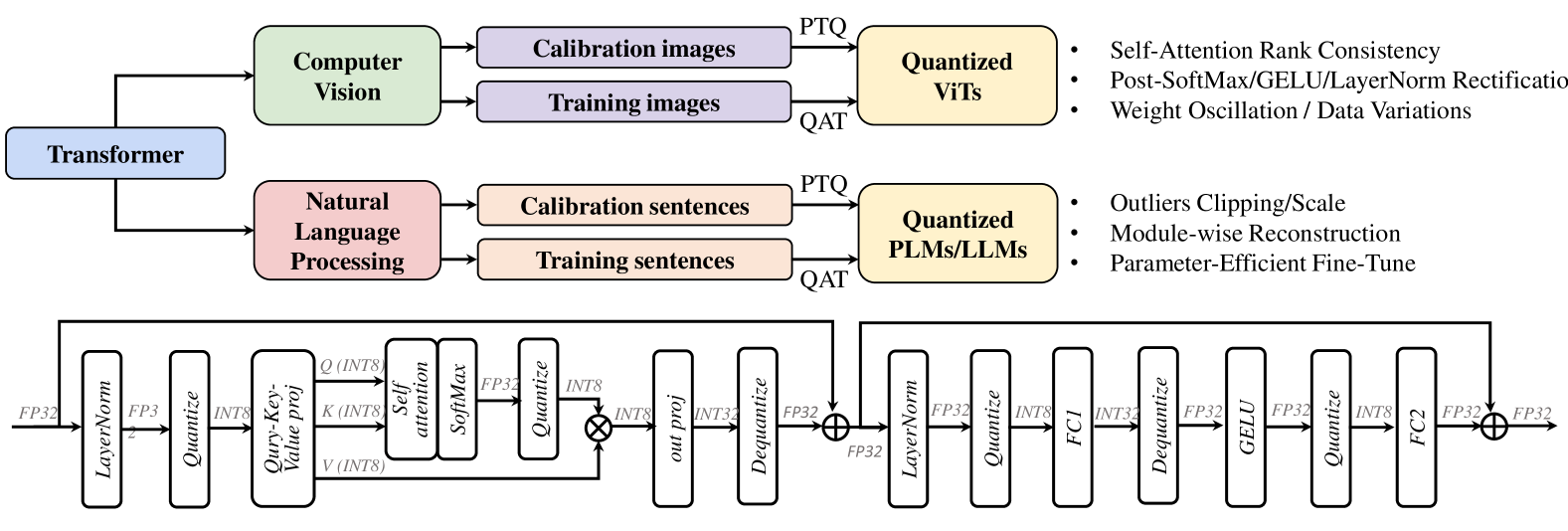
The image depicts a technical flowchart illustrating a hybrid model architecture that integrates computer vision (CV) and natural language processing (NLP) components. The system processes calibration and training data through specialized modules (Quantized ViTs for CV, Quantized PLMs/LLMs for NLP) before feeding into a Transformer-based architecture. The lower section details the Transformer's internal operations, including layer normalization, attention mechanisms, and quantization steps.
### Components/Axes
#### Main Sections
1. **Computer Vision (Green)**
- **Inputs**: Calibration images, Training images
- **Output**: Quantized ViTs (via PTQ/QAT)
- **Key Techniques**: Self-Attention Rank Consistency, Post-SoftMax/GELU/LayerNorm Rectification, Weight Oscillation/Data Variations
2. **Natural Language Processing (Pink)**
- **Inputs**: Calibration sentences, Training sentences
- **Output**: Quantized PLMs/LLMs (via PTQ/QAT)
- **Key Techniques**: Outliers Clipping/Scale, Module-wise Reconstruction, Parameter-Efficient Fine-Tune
3. **Transformer Architecture (Blue/Purple)**
- **Core Components**: LayerNorm, Quantize, Self-Attention, SoftMax, GELU, FCI, Dequantize
- **Operations**: INT8/INT32 quantization, matrix projections (INT8→INT32), cross-module interactions
#### Legend Colors
- **Green**: Computer Vision elements
- **Purple**: Training data inputs
- **Pink**: NLP elements
- **Yellow**: Quantized model outputs
- **Blue**: Transformer architecture components
### Detailed Analysis
#### Upper Flowchart
- **Calibration vs. Training Data**: Both CV and NLP modules receive separate calibration and training inputs, suggesting a two-stage optimization process.
- **Quantization Methods**:
- **PTQ (Post-Training Quantization)**: Applied to CV's ViTs and NLP's PLMs/LLMs.
- **QAT (Quantization-Aware Training)**: Implied for model optimization.
- **Model-Specific Techniques**:
- CV: Focus on attention rank consistency and weight rectification.
- NLP: Emphasis on outlier handling and parameter efficiency.
#### Lower Transformer Diagram
- **Sequential Operations**:
1. **LayerNorm** → **Quantize** (INT8) → **Query-Key Value Projection** (INT8)
2. **Self-Attention** → **SoftMax** → **FP32** normalization
3. **Cross-Module Interactions**:
- **INT8→INT32** projections between modules
- **GELU activation** and **FCI** (Feed-Forward Component)
4. **Final Output**: FP32 normalization after cross-module processing
#### Key Technical Details
- **Quantization Levels**:
- INT8 (8-bit integer) for initial layers
- FP32 (32-bit float) for critical operations (e.g., SoftMax, final output)
- **Attention Mechanisms**:
- Self-Attention Rank Consistency ensures stable feature relationships.
- Cross-module attention via **INT8→INT32** projections.
- **Efficiency Techniques**:
- Parameter-Efficient Fine-Tune (NLP)
- Module-wise Reconstruction (NLP)
### Key Observations
1. **Hybrid Architecture**: Combines CV (ViTs) and NLP (PLMs/LLMs) models, unified under a Transformer framework.
2. **Quantization Focus**: Heavy emphasis on INT8 quantization for efficiency, with FP32 reserved for precision-critical steps.
3. **Attention Complexity**: Multiple attention variants (Self-Attention, Cross-Module) with rectification techniques.
4. **Data Handling**:
- Outliers Clipping/Scale (NLP)
- Weight Oscillation/Data Variations (CV)
### Interpretation
This architecture demonstrates a **multi-modal optimization strategy** where CV and NLP models are independently quantized but integrated via a shared Transformer backbone. The use of **Post-SoftMax/GELU/LayerNorm Rectification** in CV and **Module-wise Reconstruction** in NLP suggests tailored approaches to maintain model stability after quantization. The Transformer's **INT8→INT32** projections indicate careful balancing between computational efficiency and precision. The **Parameter-Efficient Fine-Tune** in NLP implies adaptability to new data with minimal resource overhead. Overall, the system prioritizes **cross-modal efficiency** while maintaining performance through specialized quantization and attention mechanisms.