\n
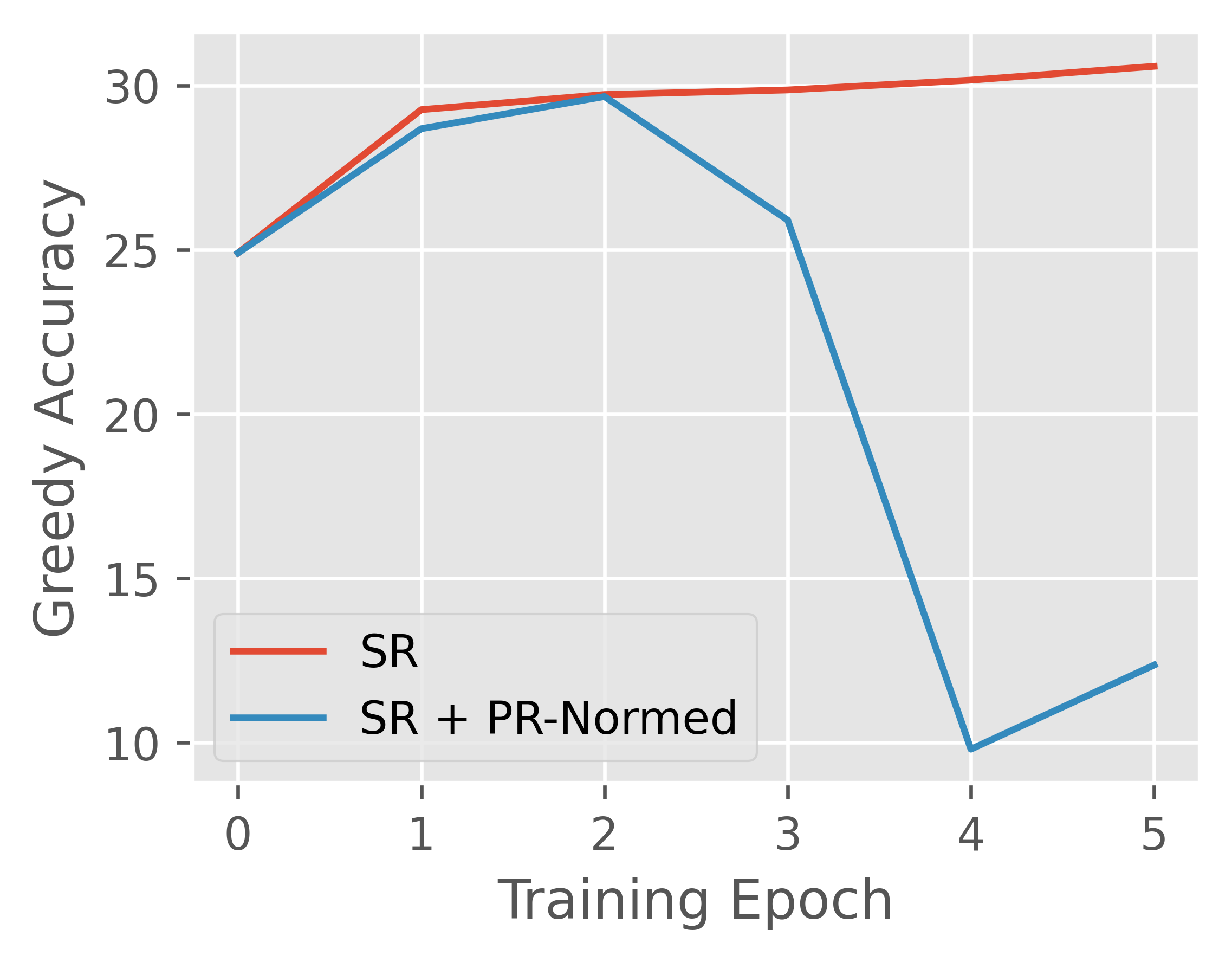
## Line Chart: Greedy Accuracy vs. Training Epoch
### Overview
This line chart depicts the relationship between Greedy Accuracy and Training Epoch for two different methods: "SR" and "SR + PR-Normed". The chart shows how the accuracy of each method changes over five training epochs.
### Components/Axes
* **X-axis:** Training Epoch, ranging from 0 to 5.
* **Y-axis:** Greedy Accuracy, ranging from 10 to 30.
* **Legend:** Located in the top-left corner, identifying the two data series:
* "SR" - represented by a red line.
* "SR + PR-Normed" - represented by a blue line.
* **Gridlines:** A light gray grid is present to aid in reading values.
### Detailed Analysis
**SR (Red Line):**
The red line representing "SR" shows a generally upward trend, starting at approximately 25.5 at epoch 0 and increasing to approximately 29.5 at epoch 5.
* Epoch 0: ~25.5
* Epoch 1: ~28.5
* Epoch 2: ~29.0
* Epoch 3: ~29.0
* Epoch 4: ~29.0
* Epoch 5: ~29.5
**SR + PR-Normed (Blue Line):**
The blue line representing "SR + PR-Normed" initially increases from approximately 25.5 at epoch 0 to a peak of approximately 29.0 at epoch 1. It then declines sharply to approximately 11 at epoch 4, before slightly increasing to approximately 12 at epoch 5.
* Epoch 0: ~25.5
* Epoch 1: ~29.0
* Epoch 2: ~27.5
* Epoch 3: ~24.0
* Epoch 4: ~11.0
* Epoch 5: ~12.0
### Key Observations
* The "SR" method demonstrates a consistent, albeit modest, increase in Greedy Accuracy over the five training epochs.
* The "SR + PR-Normed" method initially performs similarly to "SR", but experiences a significant drop in accuracy after epoch 1.
* The "SR + PR-Normed" method's accuracy at epoch 4 is substantially lower than both methods at any other epoch.
### Interpretation
The data suggests that while the "SR + PR-Normed" method starts with comparable performance to the "SR" method, it becomes unstable and loses accuracy during training. This could indicate issues with the PR-Normed component, such as overfitting or sensitivity to initial conditions. The consistent improvement of the "SR" method suggests it is a more robust approach for this particular task. The sharp decline in "SR + PR-Normed" after epoch 1 is a notable anomaly that warrants further investigation. It's possible that the PR-Normed component introduces a regularization effect that initially helps, but then hinders performance as training progresses. The difference in performance between the two methods highlights the importance of careful evaluation and tuning of different training strategies.