TECHNICAL ASSET FINGERPRINT
3c86e0de7dd3572121b3b62c
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-3.1-pro-preview VERSION 1
RUNTIME: gemini/gemini-3.1-pro-preview
INTEL_VERIFIED
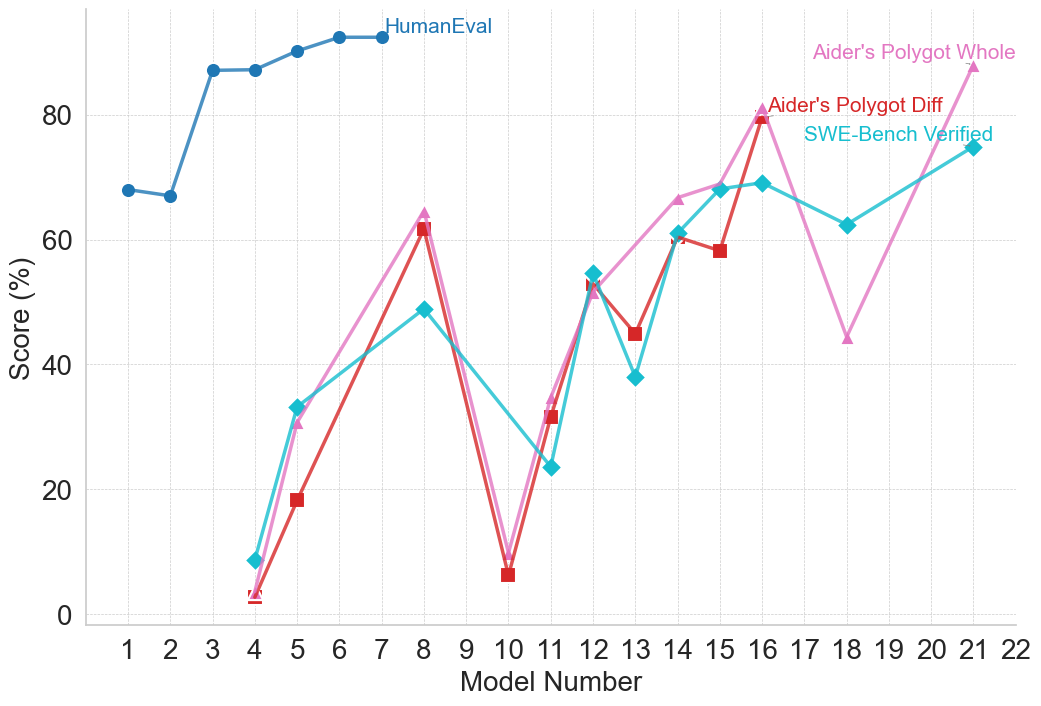
## Line Chart: Model Performance Scores Across Different Benchmarks
### Overview
This image is a line chart displaying the performance scores (in percentages) of various numbered models across four different evaluation benchmarks. The chart illustrates how performance varies significantly depending on the specific benchmark being tested, with one benchmark showing consistently high scores early on, while the other three exhibit high volatility across a wider range of models.
### Components/Axes
**1. Y-Axis (Vertical):**
* **Label:** "Score (%)"
* **Scale:** Linear, ranging from 0 to roughly 100.
* **Markers:** Major tick marks and faint horizontal dashed gridlines are present at 0, 20, 40, 60, and 80.
**2. X-Axis (Horizontal):**
* **Label:** "Model Number"
* **Scale:** Discrete integer values.
* **Markers:** Tick marks and faint vertical dashed gridlines are present for every integer from 1 to 22.
**3. Legend / Data Series Labels (Inline Spatial Grounding):**
Instead of a traditional separate legend box, the labels are placed directly on the chart area, adjacent to their respective data lines.
* **Top-Center:** "HumanEval" (Dark Blue text, corresponds to the dark blue line with circle markers).
* **Top-Right:** "Aider's Polygot Whole" (Pink text, corresponds to the pink line with triangle markers).
* **Upper-Right:** "Aider's Polygot Diff" (Red text, corresponds to the red line with square markers).
* **Upper-Right (below Red):** "SWE-Bench Verified" (Cyan text, corresponds to the cyan line with diamond markers).
---
### Detailed Analysis
*Note: All numerical values extracted from the chart are approximate (denoted by ~) based on visual interpolation between the gridlines.*
**Series 1: HumanEval**
* **Visual Attributes:** Dark blue line, solid circle markers.
* **Trend Verification:** This line appears only on the left side of the chart. It starts relatively high, dips slightly, experiences a sharp upward step, and then plateaus at a very high score.
* **Data Points:**
* Model 1: ~68%
* Model 2: ~67%
* Model 3: ~87%
* Model 4: ~87%
* Model 5: ~90%
* Model 6: ~92%
* Model 7: ~92% (Line terminates here)
**Series 2: Aider's Polygot Whole**
* **Visual Attributes:** Pink line, solid upward-pointing triangle markers.
* **Trend Verification:** This line exhibits extreme volatility. It starts near zero, spikes up, crashes back down near zero, climbs steadily with a slight dip, crashes again, and finally spikes to its highest point.
* **Data Points:**
* Model 4: ~3%
* Model 5: ~31%
* Model 8: ~64%
* Model 10: ~9%
* Model 11: ~34%
* Model 12: ~52%
* Model 14: ~66%
* Model 15: ~69%
* Model 16: ~81%
* Model 18: ~44%
* Model 21: ~88%
**Series 3: Aider's Polygot Diff**
* **Visual Attributes:** Red line, solid square markers.
* **Trend Verification:** This line closely tracks the shape and trajectory of the "Aider's Polygot Whole" (pink) line, though it generally scores slightly lower and includes a data point at Model 13 that the pink line lacks. It terminates earlier than the pink line.
* **Data Points:**
* Model 4: ~3%
* Model 5: ~18%
* Model 8: ~62%
* Model 10: ~6%
* Model 11: ~32%
* Model 12: ~53%
* Model 13: ~45%
* Model 14: ~61%
* Model 15: ~58%
* Model 16: ~80% (Line terminates here)
**Series 4: SWE-Bench Verified**
* **Visual Attributes:** Cyan line, solid diamond markers.
* **Trend Verification:** This line follows a generally upward but highly erratic trajectory. It shares some directional movements with the Aider lines (e.g., the drop at Model 11, the peak at Model 16) but diverges significantly at other points (e.g., it drops at Model 13 while others rise/are absent, and it rises at Model 18 while the pink line crashes).
* **Data Points:**
* Model 4: ~9%
* Model 5: ~33%
* Model 8: ~49%
* Model 11: ~24%
* Model 12: ~55%
* Model 13: ~38%
* Model 14: ~61%
* Model 15: ~68%
* Model 16: ~69%
* Model 18: ~62%
* Model 21: ~75%
---
### Key Observations
1. **Benchmark Difficulty Disparity:** The "HumanEval" benchmark yields vastly higher scores for early models (Models 1-7) compared to the other three benchmarks, which start near zero for Model 4.
2. **High Correlation:** The "Aider's Polygot Whole" (pink) and "Aider's Polygot Diff" (red) benchmarks are highly correlated in their trends, moving up and down in tandem, with the "Whole" metric generally scoring slightly higher.
3. **Missing Data / Sparse Testing:** The x-axis is continuous (1-22), but the data points are sparse. For example, no models were tested on the bottom three benchmarks between Models 5 and 8, or Models 8 and 10. Furthermore, not all models were tested on all benchmarks (e.g., Model 13 has data for Red and Cyan, but not Pink).
4. **Convergence Point:** At Model 12, the three lower benchmarks (Pink, Red, Cyan) converge tightly, all scoring between ~52% and ~55%.
5. **Extreme Volatility:** Models 8, 10, and 11 show massive swings in capability. Model 8 performs relatively well (~50-64%), Model 10 fails drastically (~6-9%), and Model 11 recovers partially (~24-34%).
---
### Interpretation
* **Evolution of Benchmarks:** The data strongly suggests a chronological or capability-based progression of Large Language Models (LLMs) or coding assistants. "HumanEval" is a well-known, older, and relatively simple coding benchmark. The fact that early models (1-7) easily achieve >90% on it, and it is not tracked for later models, implies it became "saturated" or too easy to be a useful metric for advanced models.
* **Introduction of Harder Tasks:** "SWE-Bench Verified" and the "Aider" benchmarks represent much more complex, real-world software engineering tasks. The low initial scores (Models 4-5) reflect this difficulty.
* **Non-Linear Model Progression:** The extreme volatility (especially the crash at Model 10 and the dip at Model 18 for the pink line) indicates that "Model Number" does not represent a strictly linear progression of capability. These numbers likely represent different model families, different sizes (e.g., 7B vs 70B parameters), or models trained with different methodologies. Model 10, for instance, might be a very small or specialized model that lacks general coding reasoning, whereas Models 16 and 21 are likely state-of-the-art, large-scale models.
* **Metric Relationships:** The tight tracking of "Aider's Polygot Whole" and "Aider's Polygot Diff" suggests they measure fundamentally similar underlying capabilities, likely the ability to generate entire files versus generating diffs/edits, with diff generation (red) appearing slightly more difficult or prone to formatting errors for the models tested.
DECODING INTELLIGENCE...