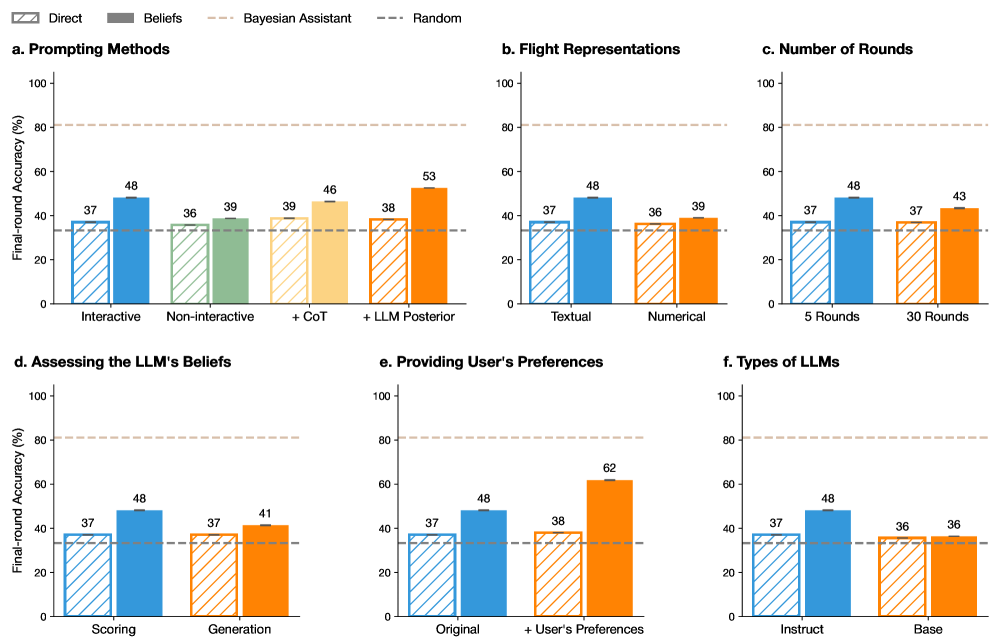
## Bar Charts: Final-Round Accuracy Comparison
### Overview
The image presents six bar charts comparing the final-round accuracy (%) of different methods and parameters related to Large Language Models (LLMs). The charts compare different prompting methods, flight representations, number of rounds, ways of assessing LLM beliefs, methods of providing user preferences, and types of LLMs. Each chart compares the "Direct" method (striped bars) with other methods (solid bars) using different colors. A horizontal dashed line represents a "Random" baseline.
### Components/Axes
* **Y-axis (all charts):** "Final-round Accuracy (%)", ranging from 0 to 100. Tick marks are not explicitly labeled, but the scale is linear.
* **Legend (top):**
* "Direct": Striped bars
* "Beliefs": Solid bars (color varies by chart)
* "Bayesian Assistant": Not explicitly represented in the charts, but implied as a comparison point.
* "Random": Dashed horizontal line.
* **Horizontal dashed lines:** Two horizontal dashed lines are present in each chart. One is at approximately 33% and is labeled "Random" in the legend. The other is at approximately 82% and is unlabeled.
* **Chart Titles:** Each chart has a title (a, b, c, d, e, f) indicating the comparison being made.
### Detailed Analysis
**a. Prompting Methods**
* X-axis: Prompting Methods (Interactive, Non-interactive, +CoT, +LLM Posterior)
* "Direct" (striped blue):
* Interactive: 37%
* Non-interactive: 36%
* +CoT: 39%
* +LLM Posterior: 38%
* "Beliefs" (solid):
* Interactive (solid blue): 48%
* Non-interactive (solid green): 39%
* +CoT (solid yellow): 46%
* +LLM Posterior (solid orange): 53%
* Trend: The "Beliefs" method generally outperforms the "Direct" method across all prompting methods.
**b. Flight Representations**
* X-axis: Flight Representations (Textual, Numerical)
* "Direct" (striped blue):
* Textual: 37%
* Numerical: 36%
* "Beliefs" (solid):
* Textual (solid blue): 48%
* Numerical (solid orange): 39%
* Trend: The "Beliefs" method outperforms the "Direct" method for both textual and numerical flight representations.
**c. Number of Rounds**
* X-axis: Number of Rounds (5 Rounds, 30 Rounds)
* "Direct" (striped blue):
* 5 Rounds: 37%
* 30 Rounds: 37%
* "Beliefs" (solid):
* 5 Rounds (solid blue): 48%
* 30 Rounds (solid orange): 43%
* Trend: The "Beliefs" method outperforms the "Direct" method for both 5 and 30 rounds.
**d. Assessing the LLM's Beliefs**
* X-axis: Assessing the LLM's Beliefs (Scoring, Generation)
* "Direct" (striped blue):
* Scoring: 37%
* Generation: 37%
* "Beliefs" (solid):
* Scoring (solid blue): 48%
* Generation (solid orange): 41%
* Trend: The "Beliefs" method outperforms the "Direct" method for both scoring and generation.
**e. Providing User's Preferences**
* X-axis: Providing User's Preferences (Original, + User's Preferences)
* "Direct" (striped blue):
* Original: 37%
* + User's Preferences: 38%
* "Beliefs" (solid):
* Original (solid blue): 48%
* + User's Preferences (solid orange): 62%
* Trend: The "Beliefs" method outperforms the "Direct" method for both original and user-preference-enhanced methods. The largest performance gap is observed when user preferences are included.
**f. Types of LLMs**
* X-axis: Types of LLMs (Instruct, Base)
* "Direct" (striped blue):
* Instruct: 37%
* Base: 36%
* "Beliefs" (solid):
* Instruct (solid blue): 48%
* Base (solid orange): 36%
* Trend: The "Beliefs" method outperforms the "Direct" method for the "Instruct" LLM type, but performs similarly for the "Base" LLM type.
### Key Observations
* The "Beliefs" method consistently outperforms the "Direct" method across most categories.
* The largest performance difference is observed in "Providing User's Preferences" when user preferences are included.
* The "Beliefs" method shows a significant advantage with the "Instruct" LLM type compared to the "Base" LLM type.
* The "Random" baseline is consistently around 33% accuracy.
### Interpretation
The data suggests that incorporating "Beliefs" into LLMs generally improves final-round accuracy compared to the "Direct" method. The improvement is particularly noticeable when providing user preferences and when using "Instruct" type LLMs. This indicates that understanding and utilizing the LLM's beliefs, especially in conjunction with user-specific information, can significantly enhance performance. The consistent outperformance over the "Random" baseline confirms that these methods are providing meaningful improvements. The "Bayesian Assistant" mentioned in the legend is not directly represented in the charts, but it likely serves as a theoretical or comparative benchmark for the other methods.