## Diagram: Neural Network Architecture
### Overview
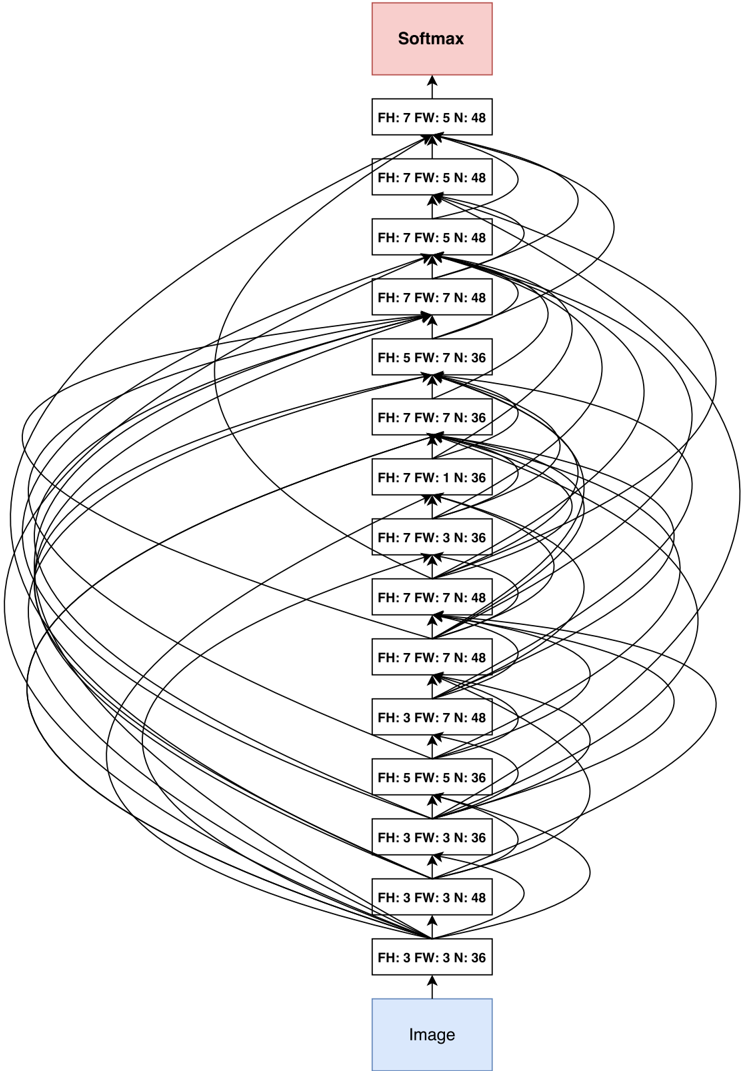
The image depicts a neural network architecture diagram. It shows the flow of data from an "Image" input through multiple layers with varying filter heights (FH), filter widths (FW), and number of nodes (N), culminating in a "Softmax" output. The diagram illustrates connections between layers, indicating a complex network structure.
### Components/Axes
* **Nodes:** Represented as rectangular boxes, each labeled with "FH: x FW: y N: z", where x, y, and z are numerical values.
* **Input:** Labeled "Image" (blue box) at the bottom of the diagram.
* **Output:** Labeled "Softmax" (red box) at the top of the diagram.
* **Connections:** Represented as black arrows indicating the flow of data between nodes.
### Detailed Analysis
The diagram consists of 16 layers, including the input and output layers. The layers are arranged vertically, with the input layer at the bottom and the output layer at the top. Each layer is connected to one or more layers above it, forming a complex network structure.
Here's a breakdown of the layers and their parameters, starting from the bottom:
1. **Image** (Input Layer, blue box)
2. **FH: 3 FW: 3 N: 36**
3. **FH: 3 FW: 3 N: 48**
4. **FH: 3 FW: 3 N: 36**
5. **FH: 5 FW: 5 N: 36**
6. **FH: 3 FW: 7 N: 48**
7. **FH: 7 FW: 7 N: 48**
8. **FH: 7 FW: 7 N: 48**
9. **FH: 7 FW: 3 N: 36**
10. **FH: 7 FW: 1 N: 36**
11. **FH: 7 FW: 7 N: 36**
12. **FH: 5 FW: 7 N: 36**
13. **FH: 7 FW: 7 N: 48**
14. **FH: 7 FW: 5 N: 48**
15. **FH: 7 FW: 5 N: 48**
16. **FH: 7 FW: 5 N: 48**
17. **Softmax** (Output Layer, red box)
The connections between layers are complex and not strictly sequential. Many layers have connections to multiple layers above them, suggesting skip connections or dense connections.
### Key Observations
* The filter height (FH), filter width (FW), and number of nodes (N) vary across different layers.
* The diagram shows a complex network architecture with multiple connections between layers.
* The input layer is labeled "Image" and the output layer is labeled "Softmax".
### Interpretation
The diagram represents a neural network architecture designed for image processing. The varying filter sizes and number of nodes in each layer suggest that the network is designed to extract features at different scales and levels of abstraction. The complex connections between layers indicate a sophisticated network structure that may be capable of learning complex patterns in the input data. The use of "Softmax" as the output layer suggests that the network is designed for classification tasks. The skip connections or dense connections may help to improve the network's performance by allowing it to learn more efficiently and avoid vanishing gradients.