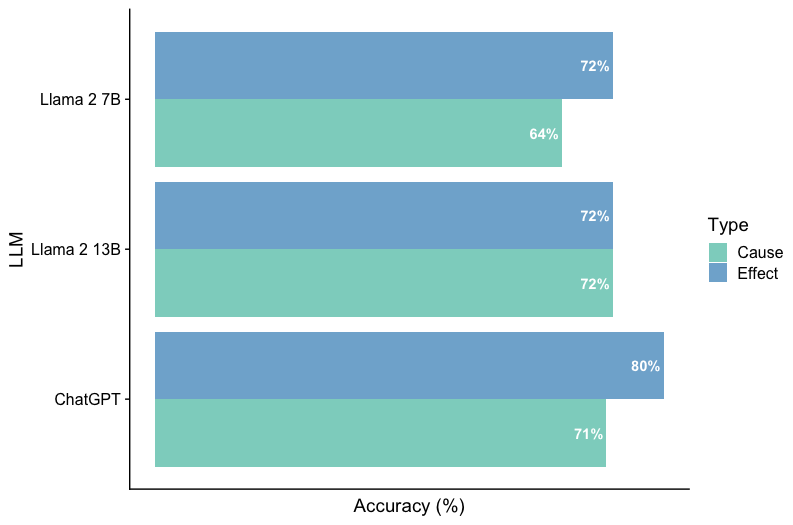
## Horizontal Bar Chart: LLM Accuracy by Type (Cause vs. Effect)
### Overview
The image is a horizontal bar chart comparing the accuracy of three Large Language Models (LLMs) - Llama 2 7B, Llama 2 13B, and ChatGPT - on two different tasks: identifying causes and identifying effects. Accuracy is measured as a percentage. The chart uses different colored bars to represent the accuracy for each task type (Cause and Effect) for each LLM.
### Components/Axes
* **Y-axis (Vertical):** Labeled "LLM", with the following categories:
* Llama 2 7B
* Llama 2 13B
* ChatGPT
* **X-axis (Horizontal):** Labeled "Accuracy (%)", representing the accuracy percentage.
* **Legend (Right Side):**
* Cause: Represented by a light green bar.
* Effect: Represented by a light blue bar.
* **Data Labels:** Accuracy percentages are displayed at the end of each bar.
### Detailed Analysis
* **Llama 2 7B:**
* Cause (light green): 64%
* Effect (light blue): 72%
* **Llama 2 13B:**
* Cause (light green): 72%
* Effect (light blue): 72%
* **ChatGPT:**
* Cause (light green): 71%
* Effect (light blue): 80%
### Key Observations
* Llama 2 13B has the same accuracy for both Cause and Effect tasks (72%).
* ChatGPT has the highest accuracy for Effect tasks (80%) compared to the other models.
* Llama 2 7B has the lowest accuracy for Cause tasks (64%) compared to the other models.
* For all models, the accuracy for identifying Effects is equal to or higher than the accuracy for identifying Causes.
### Interpretation
The chart suggests that different LLMs have varying levels of accuracy in identifying causes and effects. ChatGPT appears to be the most accurate at identifying effects, while Llama 2 7B struggles more with identifying causes. The consistent accuracy of Llama 2 13B across both tasks is also noteworthy. The data implies that the type of task (Cause vs. Effect) can influence the performance of an LLM. Further investigation could explore the specific characteristics of these tasks that lead to the observed differences in accuracy.