\n
## Horizontal Bar Chart: LLM Accuracy Comparison
### Overview
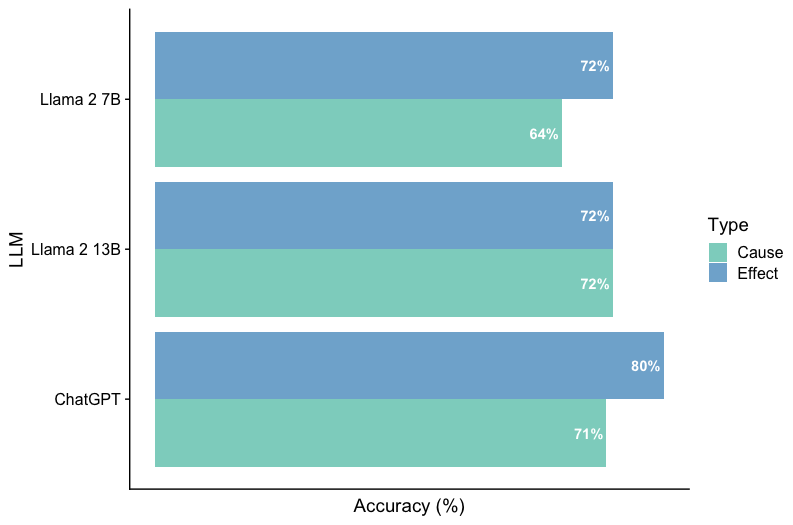
This horizontal bar chart compares the accuracy of three Large Language Models (LLMs) – Llama 2 7B, Llama 2 13B, and ChatGPT – across two types of reasoning: "Cause" and "Effect". Accuracy is measured as a percentage.
### Components/Axes
* **Y-axis:** LLM (Llama 2 7B, Llama 2 13B, ChatGPT)
* **X-axis:** Accuracy (%) - ranging from approximately 60% to 80%.
* **Legend:** Located in the top-right corner, defining the color coding for "Type":
* Cause: Light Green
* Effect: Medium Blue
* **Data Series:** Two horizontal bars for each LLM, representing accuracy for "Cause" and "Effect" reasoning.
### Detailed Analysis
The chart presents accuracy data for each LLM and reasoning type.
* **Llama 2 7B:**
* Cause: Approximately 64% accuracy. The light green bar extends to the 64% mark on the x-axis.
* Effect: Approximately 72% accuracy. The medium blue bar extends to the 72% mark on the x-axis.
* **Llama 2 13B:**
* Cause: Approximately 72% accuracy. The light green bar extends to the 72% mark on the x-axis.
* Effect: Approximately 72% accuracy. The medium blue bar extends to the 72% mark on the x-axis.
* **ChatGPT:**
* Cause: Approximately 71% accuracy. The light green bar extends to the 71% mark on the x-axis.
* Effect: Approximately 80% accuracy. The medium blue bar extends to the 80% mark on the x-axis.
### Key Observations
* ChatGPT demonstrates the highest accuracy for "Effect" reasoning at approximately 80%.
* Llama 2 13B shows consistent accuracy across both "Cause" and "Effect" reasoning, at approximately 72%.
* Llama 2 7B has the lowest accuracy for "Cause" reasoning at approximately 64%.
* The difference in accuracy between "Cause" and "Effect" reasoning is most pronounced for Llama 2 7B and ChatGPT.
### Interpretation
The data suggests that ChatGPT excels in "Effect" reasoning, significantly outperforming the other models in this area. Llama 2 13B exhibits a balanced performance across both reasoning types. Llama 2 7B appears to struggle more with "Cause" reasoning compared to "Effect" reasoning. The consistent performance of Llama 2 13B might indicate that increasing model size improves reasoning capabilities, but ChatGPT's performance suggests that architectural differences or training data also play a crucial role. The disparity in accuracy between reasoning types could be due to the inherent complexity of identifying causal relationships versus understanding effects. The chart provides a comparative snapshot of LLM performance on these specific reasoning tasks, highlighting strengths and weaknesses of each model.