## Bar Chart: Model Accuracy Comparison by Task Type
### Overview
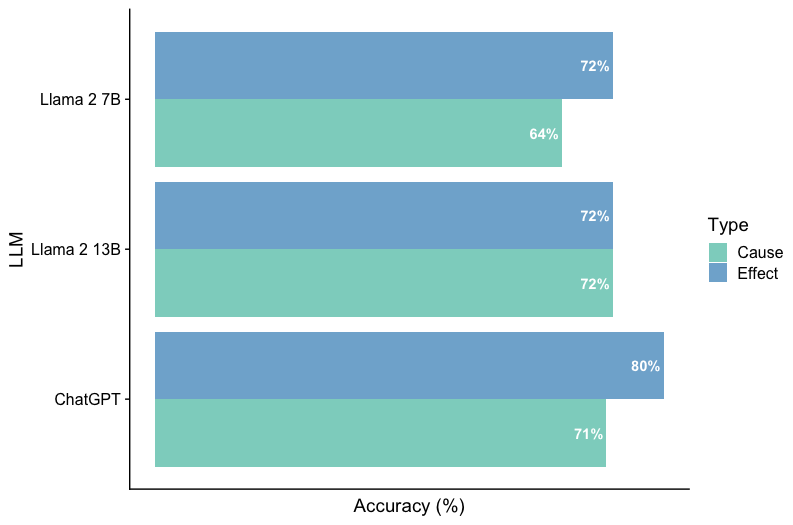
The chart compares the accuracy percentages of three language models (Llama 2 7B, Llama 2 13B, and ChatGPT) across two task types: "Cause" and "Effect." The data is presented as horizontal bars with color-coded categories (green for Cause, blue for Effect) and includes numerical labels for each bar.
### Components/Axes
- **Y-Axis**: Model names (Llama 2 7B, Llama 2 13B, ChatGPT), ordered from top to bottom.
- **X-Axis**: Accuracy (%) ranging from 0% to 80%.
- **Legend**: Located on the right, with green representing "Cause" and blue representing "Effect."
- **Bars**: Horizontal bars grouped by model, with two bars per model (one for Cause, one for Effect).
### Detailed Analysis
- **Llama 2 7B**:
- Cause: 64% (green bar).
- Effect: 72% (blue bar).
- **Llama 2 13B**:
- Cause: 72% (green bar).
- Effect: 72% (blue bar).
- **ChatGPT**:
- Cause: 71% (green bar).
- Effect: 80% (blue bar).
### Key Observations
1. **Effect Accuracy Dominance**: All models show higher accuracy for "Effect" tasks compared to "Cause" tasks, except Llama 2 13B, where both task types have equal accuracy (72%).
2. **ChatGPT Superiority**: ChatGPT achieves the highest accuracy overall (80% for Effect), significantly outperforming the Llama models.
3. **Llama Model Disparity**: Llama 2 7B has the lowest Cause accuracy (64%), while Llama 2 13B matches ChatGPT in Cause accuracy (72%).
### Interpretation
The data suggests that language models generally perform better at predicting "Effect" outcomes than "Cause" relationships. ChatGPT demonstrates superior performance across both task types, potentially due to its larger scale or training data. The Llama 2 13B model uniquely balances Cause and Effect accuracy, indicating architectural or training optimizations for parity. The disparity in Llama 2 7B's Cause accuracy highlights potential limitations in smaller models for causal reasoning tasks. These trends underscore the importance of model architecture and scale in handling different reasoning paradigms.