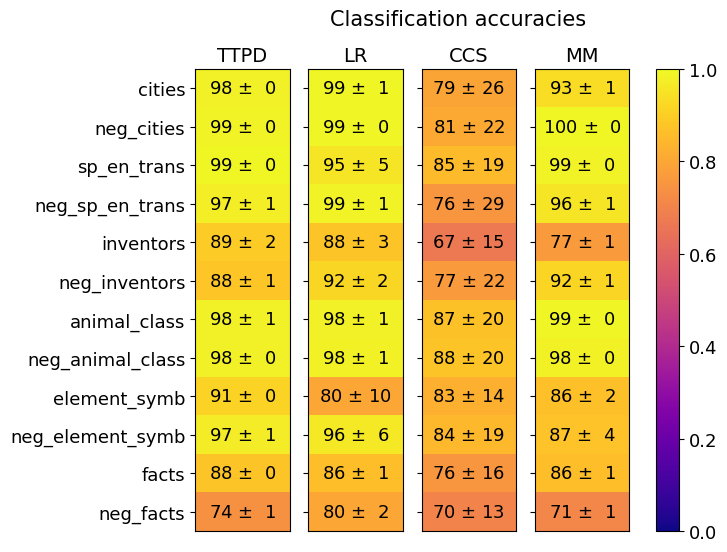
## Heatmap: Classification Accuracies
### Overview
The image is a heatmap titled "Classification accuracies" that displays the performance of four different methods (TTPD, LR, CCS, MM) across twelve distinct datasets or tasks. Performance is measured as a mean accuracy percentage with an associated standard deviation (e.g., "98 ± 0"). The color of each cell corresponds to the mean accuracy value, with a color scale provided on the right.
### Components/Axes
* **Title:** "Classification accuracies" (centered at the top).
* **Column Headers (Methods):** Four columns labeled from left to right: "TTPD", "LR", "CCS", "MM".
* **Row Labels (Datasets/Tasks):** Twelve rows labeled from top to bottom:
1. `cities`
2. `neg_cities`
3. `sp_en_trans`
4. `neg_sp_en_trans`
5. `inventors`
6. `neg_inventors`
7. `animal_class`
8. `neg_animal_class`
9. `element_symb`
10. `neg_element_symb`
11. `facts`
12. `neg_facts`
* **Color Scale/Legend:** A vertical color bar located on the far right of the chart. It ranges from 0.0 (dark purple/blue) at the bottom to 1.0 (bright yellow) at the top, with intermediate colors of purple, red, and orange. This scale maps the cell color to the mean accuracy value (where 1.0 = 100% accuracy).
* **Cell Content:** Each cell in the 12x4 grid contains a text string in the format "[Mean Accuracy] ± [Standard Deviation]". The mean is an integer percentage (0-100), and the standard deviation is also an integer.
### Detailed Analysis
Below is the complete transcription of the data grid, organized by row (dataset) and column (method). Values are presented as "Mean ± Std Dev".
| Dataset / Task | TTPD | LR | CCS | MM |
| :--- | :--- | :--- | :--- | :--- |
| **cities** | 98 ± 0 | 99 ± 1 | 79 ± 26 | 93 ± 1 |
| **neg_cities** | 99 ± 0 | 99 ± 0 | 81 ± 22 | 100 ± 0 |
| **sp_en_trans** | 99 ± 0 | 95 ± 5 | 85 ± 19 | 99 ± 0 |
| **neg_sp_en_trans** | 97 ± 1 | 99 ± 1 | 76 ± 29 | 96 ± 1 |
| **inventors** | 89 ± 2 | 88 ± 3 | 67 ± 15 | 77 ± 1 |
| **neg_inventors** | 88 ± 1 | 92 ± 2 | 77 ± 22 | 92 ± 1 |
| **animal_class** | 98 ± 1 | 98 ± 1 | 87 ± 20 | 99 ± 0 |
| **neg_animal_class** | 98 ± 0 | 98 ± 1 | 88 ± 20 | 98 ± 0 |
| **element_symb** | 91 ± 0 | 80 ± 10 | 83 ± 14 | 86 ± 2 |
| **neg_element_symb** | 97 ± 1 | 96 ± 6 | 84 ± 19 | 87 ± 4 |
| **facts** | 88 ± 0 | 86 ± 1 | 76 ± 16 | 86 ± 1 |
| **neg_facts** | 74 ± 1 | 80 ± 2 | 70 ± 13 | 71 ± 1 |
**Trend Verification by Column (Method):**
* **TTPD:** The column is predominantly bright yellow, indicating consistently high accuracy (mostly 88-99%). The trend is stable with very low standard deviations (0-2). The lowest point is for `neg_facts` (74 ± 1).
* **LR:** Also predominantly yellow, showing high accuracy (80-99%). It has slightly more variation than TTPD, with a notable dip for `element_symb` (80 ± 10) and a high standard deviation there.
* **CCS:** This column shows the most color variation, from orange to red, indicating lower and more variable performance (67-88%). Standard deviations are consistently high (13-29), suggesting unstable results. The lowest accuracy is for `inventors` (67 ± 15).
* **MM:** Mostly yellow with some orange, indicating good to excellent performance (71-100%). It achieves a perfect score on `neg_cities` (100 ± 0). The lowest performance is on `neg_facts` (71 ± 1).
### Key Observations
1. **Method Performance Hierarchy:** TTPD and LR are the top-performing methods, achieving near-perfect accuracy on many tasks. MM is generally strong but slightly less consistent. CCS is the clear underperformer with significantly lower mean accuracies and much higher variance.
2. **Dataset Difficulty:** The `inventors` and `neg_inventors` tasks appear challenging for all methods, yielding the lowest scores in their respective rows for TTPD, LR, and CCS. The `neg_facts` task also shows uniformly lower performance.
3. **Negation Effect:** For most dataset pairs (e.g., `cities`/`neg_cities`), the performance on the negated version is comparable to or sometimes better than the original (e.g., MM on `neg_cities` vs. `cities`). A notable exception is `element_symb` vs. `neg_element_symb` for TTPD and LR, where the negated version shows higher accuracy.
4. **Stability (Standard Deviation):** TTPD and MM exhibit very low standard deviations (mostly 0-2), indicating highly stable and reproducible results. LR is stable except for `element_symb`. CCS has high standard deviations across the board, indicating high result variability or sensitivity to data splits.
### Interpretation
This heatmap provides a comparative benchmark of four classification methods across a diverse set of tasks, likely from a machine learning or natural language processing study. The data suggests that **TTPD and LR are robust, high-performing, and stable methods** for these specific tasks. Their near-ceiling performance on many datasets indicates the tasks may be relatively straightforward for these models, or the models are exceptionally well-suited.
The **poor and variable performance of CCS** is a critical finding. It suggests this method either lacks the capacity for these tasks, is poorly tuned, or is fundamentally less suitable for the data types represented (which include geographical, translational, biological, and factual knowledge). The high standard deviations for CCS could point to overfitting or instability in its training process.
The **consistent challenge posed by the `inventors` and `facts` datasets** (and their negations) implies these tasks involve more complex, nuanced, or sparse information that is harder for all models to capture reliably. The fact that negation often does not significantly degrade performance (and sometimes improves it) is intriguing; it may indicate that the models are learning robust representations of the underlying concepts rather than relying on simple surface patterns.
In a research context, this chart would be used to argue for the superiority of TTPD/LR over CCS on this benchmark suite and to highlight specific task difficulties that warrant further investigation. The perfect score of MM on `neg_cities` (100 ± 0) is a standout result that merits examination of both the method and the dataset's properties.