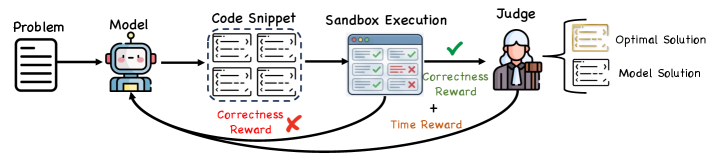
## Diagram: Model Evaluation Workflow
### Overview
The image illustrates a workflow for evaluating a model's performance on a given problem. The workflow involves generating code snippets, executing them in a sandbox environment, and judging their correctness against an optimal solution. Rewards are given based on correctness and time.
### Components/Axes
* **Problem:** A document with lines of text, representing the task or challenge.
* **Model:** A robot-like figure, representing the AI model being evaluated.
* **Code Snippet:** A dashed-line box containing four code snippets, each represented by lines of code.
* **Sandbox Execution:** A computer screen showing the execution of the code snippets, with checkmarks indicating successful tests and X marks indicating failed tests.
* **Judge:** A figure dressed as a judge, holding a gavel.
* **Optimal Solution:** A document representing the ideal solution to the problem.
* **Model Solution:** A document representing the solution generated by the model.
* **Correctness Reward:** Text label with an arrow pointing back to the model.
* **Time Reward:** Text label with an arrow pointing back to the model.
### Detailed Analysis
1. **Workflow:**
* The workflow starts with a "Problem" which is fed into a "Model".
* The "Model" generates "Code Snippets".
* The "Code Snippets" are executed in a "Sandbox Execution" environment.
* The results of the "Sandbox Execution" are evaluated by a "Judge".
* The "Judge" compares the "Model Solution" with the "Optimal Solution".
2. **Feedback Loop:**
* If the "Code Snippets" are incorrect, a "Correctness Reward" is given back to the "Model" with a red X indicating a negative reward.
* If the "Code Snippets" are correct, a "Correctness Reward" and "Time Reward" are given back to the "Model" with a green checkmark indicating a positive reward.
3. **Sandbox Execution Details:**
* The "Sandbox Execution" screen shows a series of tests.
* Some tests are marked with green checkmarks, indicating success.
* Some tests are marked with red X marks, indicating failure.
* The top two tests are successful, while the bottom two tests are failures.
### Key Observations
* The diagram highlights the iterative nature of model evaluation, with feedback loops based on correctness and time.
* The "Sandbox Execution" component provides a visual representation of the model's performance on individual tests.
* The "Judge" component represents the evaluation process, comparing the model's solution to the optimal solution.
### Interpretation
The diagram illustrates a reinforcement learning or iterative development process where a model attempts to solve a problem, generates code, and receives feedback based on the correctness and efficiency of its solution. The "Sandbox Execution" provides a controlled environment for testing the code, and the "Judge" acts as the evaluator, providing rewards to the model to improve its performance over time. The presence of both "Correctness Reward" and "Time Reward" suggests that the model is being optimized not only for accuracy but also for efficiency. The negative "Correctness Reward" indicates a penalty for incorrect solutions, encouraging the model to learn from its mistakes.