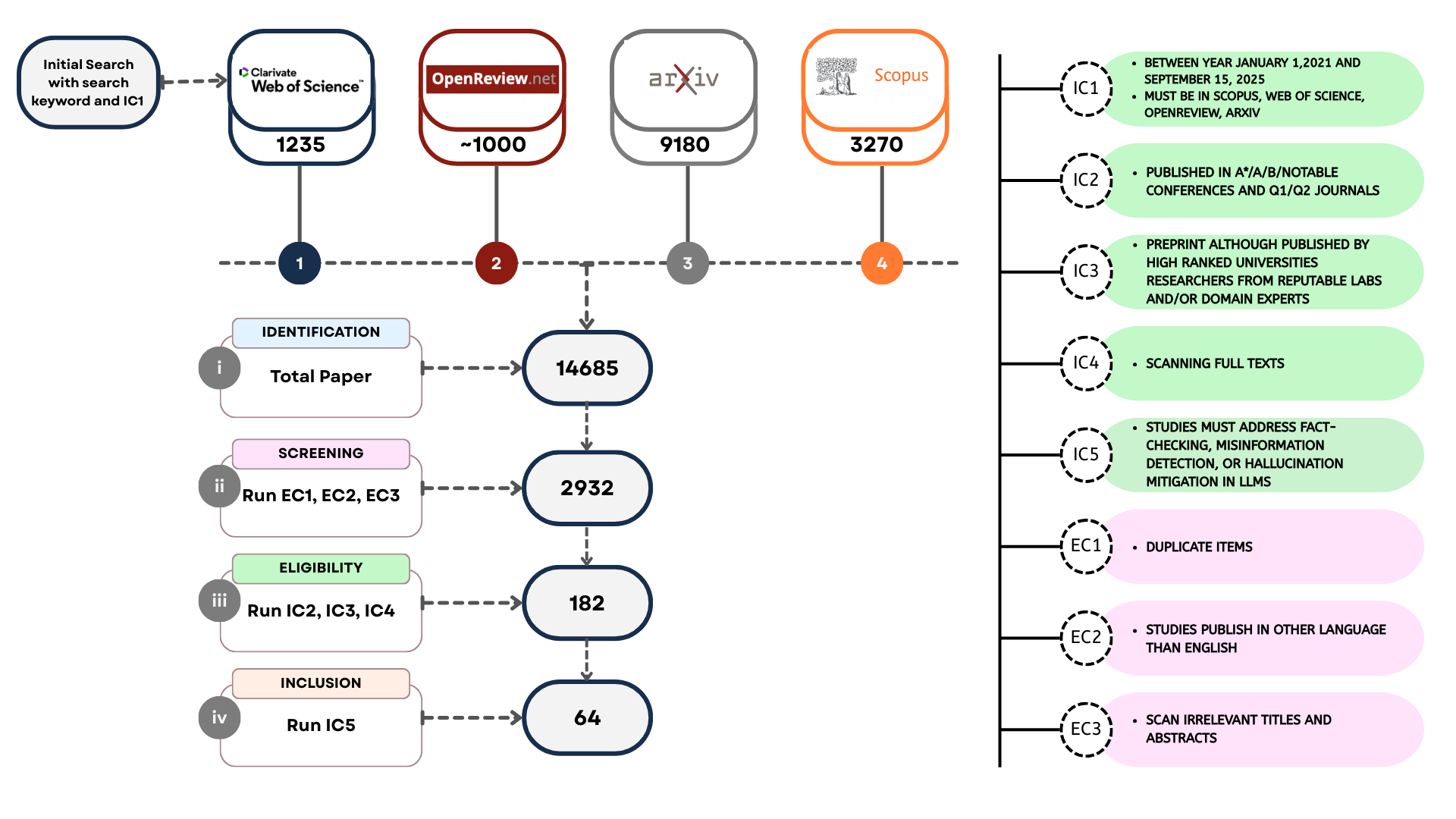
## Flowchart: Research Study Selection Process for LLM Hallucination Mitigation
### Overview
The flowchart illustrates a multi-stage research study selection process for evaluating hallucination mitigation techniques in Large Language Models (LLMs). It begins with an initial search across four academic databases, followed by systematic screening, eligibility assessment, and final inclusion criteria application. The right panel details specific inclusion criteria (IC1-IC5) with color-coded annotations.
### Components/Axes
**Left Panel (Flowchart):**
1. **Initial Search (Stage 1):**
- Databases: Clarivate Web of Science (1235), OpenReview.net (~1000), arXiv (9180), Scopus (3270)
- Total papers identified: 14,685
2. **Screening (Stage 2):**
- Exclusion Criteria (EC1-EC3): Duplicate items, non-English publications, irrelevant titles/abstracts
- Papers after screening: 2,932
3. **Eligibility (Stage 3):**
- Inclusion Criteria (IC2-IC4): Published in A*/A/B journals/conferences, preprints from reputable institutions, full-text scanning
- Papers after eligibility: 182
4. **Inclusion (Stage 4):**
- Inclusion Criterion (IC5): Studies addressing fact-checking, misinformation detection, or hallucination mitigation in LLMs
- Final included studies: 64
**Right Panel (Inclusion Criteria):**
- **IC1:** Publication date between January 1, 2021, and September 15, 2025; must be in Scopus, Web of Science, OpenReview, or arXiv
- **IC2:** Published in A*/A/B notable conferences or Q1/Q2 journals
- **IC3:** Preprints from high-ranked universities/researchers in reputable labs/domain experts
- **IC4:** Full-text scanning requirement
- **IC5:** Focus on fact-checking, misinformation detection, or hallucination mitigation in LLMs
### Detailed Analysis
- **Initial Search:**
- arXiv contributes the most papers (9180), followed by Scopus (3270), Web of Science (1235), and OpenReview.net (~1000)
- Total papers: 14,685 (sum of all database contributions)
- **Screening Process:**
- EC1 (duplicates), EC2 (non-English), EC3 (irrelevant titles/abstracts) reduce the pool from 14,685 to 2,932
- Color coding: Pink for screening criteria
- **Eligibility Assessment:**
- IC2 (publication venue), IC3 (institution reputation), IC4 (full-text access) filter to 182 papers
- Color coding: Green for eligibility criteria
- **Final Inclusion:**
- IC5 (LLM hallucination focus) selects 64 studies
- Color coding: Light blue for inclusion criteria
### Key Observations
1. **Publication Venue Concentration:**
- arXiv dominates initial search (62.5% of total papers)
- Scopus and Web of Science together represent 22.3%
2. **Screening Efficiency:**
- 80.3% of papers eliminated during screening (11,753 removed)
3. **Eligibility Stringency:**
- Only 12.4% of screened papers (182/1468) meet eligibility criteria
4. **Final Selection:**
- 35.2% of eligible papers (64/182) satisfy IC5 requirements
### Interpretation
This flowchart demonstrates a rigorous, multi-phase selection process typical of systematic reviews in computational linguistics. The hierarchical filtering:
1. **Broadens scope** through multi-database searches
2. **Applies venue-based filters** (IC1-IC4) to ensure academic rigor
3. **Focuses on technical relevance** through IC5's LLM-specific requirements
The color-coded annotations (pink/green/blue) spatially ground the criteria application across stages. Notably, the 64 final studies represent 0.44% of the initial search corpus, highlighting the challenges in LLM research reproducibility and the need for standardized evaluation frameworks. The emphasis on preprints (IC3) and full-text access (IC4) suggests an attempt to balance academic rigor with practical accessibility in this rapidly evolving field.