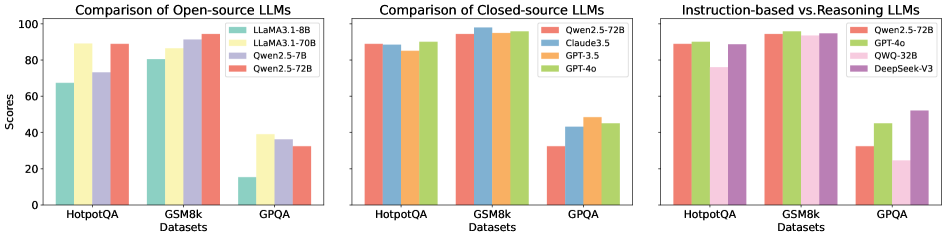
## Bar Charts: LLM Performance Comparison
### Overview
The image presents three bar charts comparing the performance of various Large Language Models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. The charts are arranged horizontally, with the first comparing open-source LLMs, the second comparing closed-source LLMs, and the third comparing instruction-based and reasoning LLMs. The y-axis represents "Scores," ranging from 0 to 100. The x-axis represents the datasets.
### Components/Axes
* **Y-axis Title:** "Scores" (Scale: 0 to 100, increments of 20)
* **X-axis Title:** "Datasets" (Categories: HotpotQA, GSM8k, GPQA)
* **Chart 1 (Open-source LLMs):**
* **Legend:**
* LLaMA3-1.8B (Blue)
* LLaMA3-1.70B (Orange)
* Qwen2.5-7B (Green)
* Qwen2.5-72B (Red)
* **Chart 2 (Closed-source LLMs):**
* **Legend:**
* Qwen2.5-72B (Yellow)
* Claude3.5 (Purple)
* GPT-3.5 (Orange)
* GPT-4o (Brown)
* **Chart 3 (Instruction-based vs. Reasoning LLMs):**
* **Legend:**
* Qwen2.5-72B (Pink)
* GPT-4o (Green)
* QWQ-32B (Blue)
* DeepSeek-V3 (Purple)
### Detailed Analysis or Content Details
**Chart 1: Comparison of Open-source LLMs**
* **HotpotQA:**
* LLaMA3-1.8B: Approximately 68
* LLaMA3-1.70B: Approximately 72
* Qwen2.5-7B: Approximately 85
* Qwen2.5-72B: Approximately 88
* **GSM8k:**
* LLaMA3-1.8B: Approximately 82
* LLaMA3-1.70B: Approximately 86
* Qwen2.5-7B: Approximately 90
* Qwen2.5-72B: Approximately 92
* **GPQA:**
* LLaMA3-1.8B: Approximately 32
* LLaMA3-1.70B: Approximately 36
* Qwen2.5-7B: Approximately 40
* Qwen2.5-72B: Approximately 30
**Chart 2: Comparison of Closed-source LLMs**
* **HotpotQA:**
* Qwen2.5-72B: Approximately 86
* Claude3.5: Approximately 92
* GPT-3.5: Approximately 88
* GPT-4o: Approximately 94
* **GSM8k:**
* Qwen2.5-72B: Approximately 88
* Claude3.5: Approximately 94
* GPT-3.5: Approximately 90
* GPT-4o: Approximately 96
* **GPQA:**
* Qwen2.5-72B: Approximately 42
* Claude3.5: Approximately 45
* GPT-3.5: Approximately 38
* GPT-4o: Approximately 48
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **HotpotQA:**
* Qwen2.5-72B: Approximately 88
* GPT-4o: Approximately 92
* QWQ-32B: Approximately 84
* DeepSeek-V3: Approximately 86
* **GSM8k:**
* Qwen2.5-72B: Approximately 94
* GPT-4o: Approximately 96
* QWQ-32B: Approximately 90
* DeepSeek-V3: Approximately 92
* **GPQA:**
* Qwen2.5-72B: Approximately 36
* GPT-4o: Approximately 48
* QWQ-32B: Approximately 32
* DeepSeek-V3: Approximately 34
### Key Observations
* GPT-4o consistently achieves the highest scores across all datasets in the closed-source and instruction-based/reasoning LLM charts.
* Qwen2.5-72B generally performs well across all datasets, particularly in the open-source chart.
* LLaMA3-1.8B and LLaMA3-1.70B consistently have the lowest scores in the open-source chart.
* Performance varies significantly across datasets. All models perform better on GSM8k than on GPQA.
* The gap in performance between models is more pronounced on the GPQA dataset.
### Interpretation
The data suggests that GPT-4o is currently the leading LLM in terms of performance on these datasets, followed closely by Claude3.5. Qwen2.5-72B is a strong performer among the open-source models. The differences in performance across datasets indicate that the difficulty of the task influences the relative ranking of the models. The lower scores on GPQA suggest that this dataset presents a greater challenge for all models, potentially due to its specific requirements or complexity. The consistent trend of GPT-4o outperforming other models suggests its superior capabilities in understanding and reasoning. The comparison between open-source and closed-source models highlights the current advantage of closed-source models, likely due to larger training datasets and more computational resources. The third chart, comparing instruction-based and reasoning LLMs, further reinforces the strength of GPT-4o and demonstrates the competitive performance of Qwen2.5-72B.