## Bar Charts: LLM Performance Comparison Across Datasets
### Overview
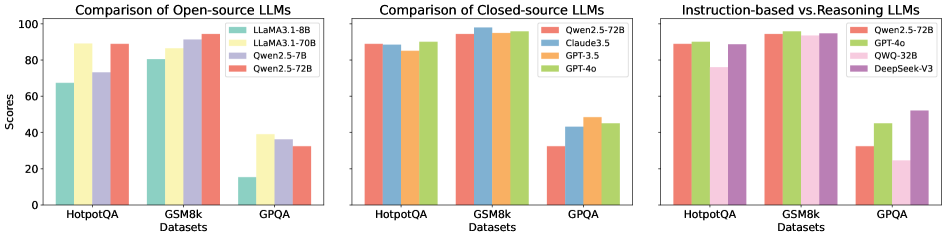
The image displays three horizontally arranged bar charts comparing the performance of various Large Language Models (LLMs) on three distinct evaluation datasets. The charts are titled "Comparison of Open-source LLMs," "Comparison of Closed-source LLMs," and "Instruction-based vs Reasoning-based LLMs." Each chart shares a common structure with the same three datasets on the x-axis and a "Scores" metric on the y-axis.
### Components/Axes
* **Common Elements (All Charts):**
* **X-axis Label:** "Datasets"
* **X-axis Categories (from left to right):** "HotpotQA", "GSM8k", "GPQA"
* **Y-axis Label:** "Scores"
* **Y-axis Scale:** 0 to 100, with major tick marks at 0, 20, 40, 60, 80, 100.
* **Chart Layout:** Three separate bar charts arranged side-by-side. Each chart has its own title and legend.
* **Chart 1: Comparison of Open-source LLMs (Left)**
* **Legend (Top-Right):**
* Teal bar: `LLaMA3.1-8B`
* Yellow bar: `LLaMA3.1-70B`
* Purple bar: `Qwen2.5-7B`
* Red bar: `Qwen2.5-72B`
* **Chart 2: Comparison of Closed-source LLMs (Center)**
* **Legend (Top-Right):**
* Red bar: `Qwen2.5-72B`
* Blue bar: `Claude3.5`
* Orange bar: `GPT-3.5`
* Green bar: `GPT-4o`
* **Chart 3: Instruction-based vs Reasoning-based LLMs (Right)**
* **Legend (Top-Right):**
* Red bar: `Qwen2.5-72B`
* Green bar: `GPT-4o`
* Pink bar: `QWO-32B`
* Purple bar: `DeepSeek-V3`
### Detailed Analysis
**Chart 1: Open-source LLMs**
* **HotpotQA:** `LLaMA3.1-70B` (yellow) and `Qwen2.5-72B` (red) are the top performers, both scoring approximately 90. `Qwen2.5-7B` (purple) scores ~75, and `LLaMA3.1-8B` (teal) scores ~65.
* **GSM8k:** All models perform strongly. `Qwen2.5-7B` (purple) and `Qwen2.5-72B` (red) are highest at ~95. `LLaMA3.1-70B` (yellow) is ~90, and `LLaMA3.1-8B` (teal) is ~80.
* **GPQA:** This is the most challenging dataset for these models. `LLaMA3.1-70B` (yellow) leads with a score of ~40. `Qwen2.5-7B` (purple) is ~35, `Qwen2.5-72B` (red) is ~30, and `LLaMA3.1-8B` (teal) is significantly lower at ~15.
**Chart 2: Closed-source LLMs**
* **HotpotQA:** Performance is tightly clustered. `Qwen2.5-72B` (red) and `GPT-4o` (green) are at ~90. `Claude3.5` (blue) is ~88, and `GPT-3.5` (orange) is ~85.
* **GSM8k:** All models achieve very high scores. `Qwen2.5-72B` (red), `Claude3.5` (blue), and `GPT-4o` (green) are all at or near ~95. `GPT-3.5` (orange) is slightly lower at ~90.
* **GPQA:** Scores are lower and more varied. `GPT-3.5` (orange) leads at ~50. `Claude3.5` (blue) and `GPT-4o` (green) are both ~45. `Qwen2.5-72B` (red) is the lowest at ~30.
**Chart 3: Instruction-based vs Reasoning-based LLMs**
* **HotpotQA:** `GPT-4o` (green) is the highest at ~92. `Qwen2.5-72B` (red) and `DeepSeek-V3` (purple) are both ~90. `QWO-32B` (pink) is notably lower at ~75.
* **GSM8k:** All four models achieve near-perfect scores of ~95.
* **GPQA:** `DeepSeek-V3` (purple) is the clear leader with a score of ~55. `GPT-4o` (green) is next at ~45. `Qwen2.5-72B` (red) is ~30, and `QWO-32B` (pink) is the lowest at ~25.
### Key Observations
1. **Dataset Difficulty:** GPQA is consistently the most difficult dataset across all model categories, yielding the lowest scores. GSM8k appears to be the easiest, with most models scoring above 80.
2. **Model Scale Impact (Chart 1):** For open-source models, the larger 70B/72B parameter models (`LLaMA3.1-70B`, `Qwen2.5-72B`) significantly outperform their smaller 7B/8B counterparts, especially on the challenging GPQA dataset.
3. **Performance Clustering:** Closed-source models (Chart 2) show very similar performance on HotpotQA and GSM8k, with differentiation only appearing on the harder GPQA task.
4. **Standout Performer:** `DeepSeek-V3` (Chart 3, purple) demonstrates a notable advantage on the GPQA dataset compared to other models in its comparison group, suggesting potential strength in complex reasoning tasks.
5. **Consistency:** `Qwen2.5-72B` (red) appears in all three charts as a benchmark, allowing for cross-category comparison. It is a top performer among open-source models and competitive with closed-source models on easier tasks but falls behind on GPQA.
### Interpretation
The data suggests a clear hierarchy of task difficulty for current LLMs, with GPQA representing a frontier challenge. The significant performance gap between model sizes in the open-source chart underscores the importance of scale for capability, particularly for complex reasoning. The tight clustering of top closed-source models indicates a competitive plateau on standard benchmarks like HotpotQA and GSM8k.
The most insightful finding is the divergent performance on GPQA. While most models struggle, `DeepSeek-V3`'s relatively high score hints at a possible architectural or training difference that confers an advantage on this specific type of reasoning task. This chart effectively isolates "reasoning" as a differentiating capability, moving beyond general instruction-following performance measured by the other datasets. The charts collectively argue that evaluating LLMs requires a suite of diverse benchmarks to reveal specific strengths and weaknesses.