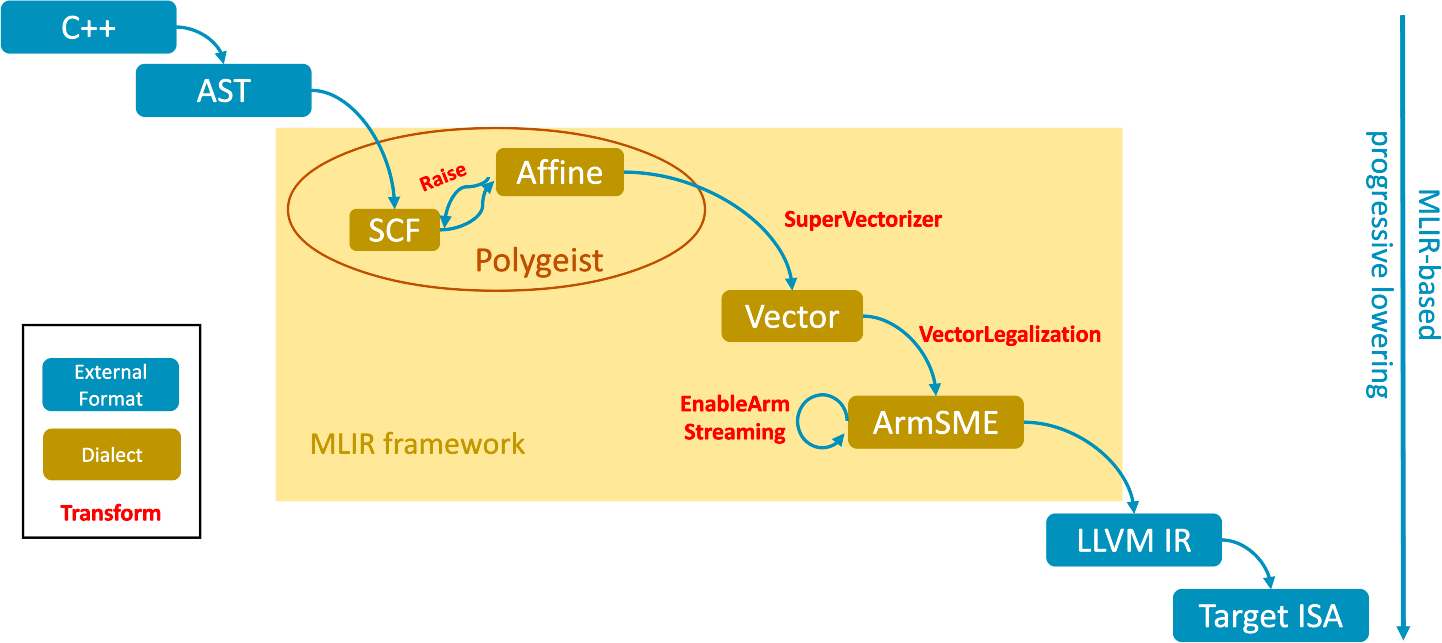
## Diagram: MLIR Framework Compilation Pipeline
### Overview
The diagram illustrates a multi-stage compilation pipeline within the MLIR (Multi-Level Intermediate Representation) framework. It shows the transformation of high-level C++ code through various intermediate representations (IRs) and optimizations, culminating in target machine code (Target ISA). The process emphasizes "progressive lowering" toward MLIR-based representations, with key components like SCF (Standardized Control Flow), Affine, and Vector optimizations.
### Components/Axes
- **Vertical Axis (Right)**: Labeled "progressive lowering," with "MLIR-based" at the top. Indicates increasing reliance on MLIR as the pipeline progresses downward.
- **Horizontal Flow (Left to Right)**: Represents the sequence of transformations from source code to target ISA.
- **Legend (Left Box)**:
- **Blue**: External Format (C++, AST)
- **Brown**: Dialect (SCF, Affine, Vector, ArmSME)
- **Red**: Transform (Raise, SuperVectorizer, VectorLegalization, EnableArmStreaming)
- **Key Components**:
- **C++ → AST**: Source code parsed into an Abstract Syntax Tree.
- **AST → SCF**: Raised to Standardized Control Flow (SCF) dialect.
- **SCF → Affine → SuperVectorizer → Vector**: Optimizations for control flow and vectorization.
- **Vector → VectorLegalization**: Legalization for target architecture.
- **EnableArmStreaming → ArmSME**: ARM-specific optimizations.
- **ArmSME → LLVM IR → Target ISA**: Final compilation to machine code.
### Detailed Analysis
- **Flow Direction**:
- Starts with C++ code, parsed into an AST (blue).
- Transforms into SCF (brown), then Affine (brown), followed by vectorization (SuperVectorizer, brown) and legalization (VectorLegalization, red).
- Enables ARM streaming (red) via ArmSME (brown), leading to LLVM IR (blue) and finally Target ISA (blue).
- **MLIR Framework**: Central to the pipeline, housing dialects like SCF, Affine, Vector, and ArmSME.
- **Progressive Lowering**: The vertical axis suggests that earlier stages (e.g., C++, AST) are less MLIR-dependent, while later stages (e.g., Vector, ArmSME) are fully MLIR-based.
### Key Observations
- **Sequential Optimization**: Each stage builds on the previous, with increasing specialization (e.g., SCF → Affine → Vector).
- **ARM Focus**: The inclusion of ArmSME and EnableArmStreaming indicates optimization for ARM architectures.
- **MLIR Integration**: The pipeline leverages MLIR’s modular design, with dialects enabling targeted optimizations.
### Interpretation
This diagram represents a compiler infrastructure using MLIR to optimize code for ARM architectures. The "progressive lowering" axis highlights how MLIR enables incremental abstraction reduction, allowing high-level optimizations (e.g., vectorization) to be applied early while retaining flexibility for target-specific adjustments (e.g., ArmSME). The flow underscores MLIR’s role in bridging high-level languages (C++) and low-level hardware (Target ISA), with dialects like SCF and Affine enabling reusable, composable optimizations. The absence of numerical data suggests this is a conceptual workflow rather than a performance benchmark.