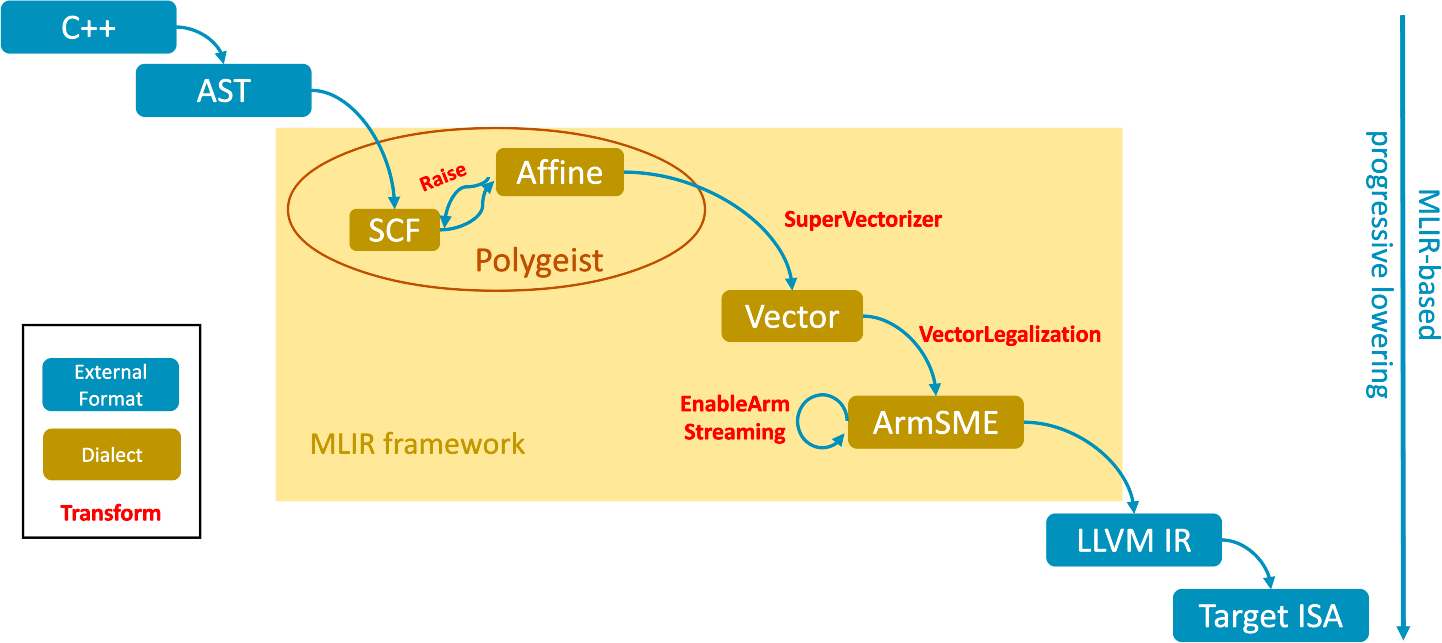
## Compiler Optimization Diagram: MLIR-based Progressive Lowering
### Overview
The image is a diagram illustrating a compiler optimization pipeline based on the MLIR (Multi-Level Intermediate Representation) framework. It shows the flow of code transformations from a high-level language (C++) down to target-specific instructions (Target ISA). The diagram highlights key stages and dialects within the MLIR framework, emphasizing progressive lowering.
### Components/Axes
* **Nodes:** Represented as rounded rectangles, these indicate different stages or dialects in the compilation process.
* **Arrows:** Indicate the flow of data and transformations between stages.
* **Text Labels:** Describe the nodes and the transformations applied.
* **Overall Direction:** The diagram flows from top to bottom, representing the progressive lowering process.
* **Right Side:** A vertical label "MLIR-based progressive lowering" indicates the overall direction and purpose of the diagram.
### Detailed Analysis or ### Content Details
1. **Top-Level Stages:**
* **C++:** The initial high-level language.
* **AST:** Abstract Syntax Tree, the first intermediate representation.
2. **MLIR Framework:**
* A large yellow rectangle labeled "MLIR framework" encompasses several stages.
* **Polygeist:** An oval shape within the MLIR framework contains:
* **SCF:** A node representing the Structured Control Flow dialect.
* **Affine:** A node representing the Affine dialect.
* An arrow labeled "Raise" connects SCF and Affine, indicating a bidirectional transformation.
3. **Vectorization Stages:**
* **Vector:** A node representing the Vector dialect.
* **ArmSME:** A node representing the Arm Scalable Matrix Extension.
* An arrow labeled "SuperVectorizer" connects Affine to Vector.
* An arrow labeled "VectorLegalization" connects Vector to ArmSME.
* An arrow labeled "EnableArm Streaming" connects ArmSME back to Vector, indicating a feedback loop.
4. **Lowering to Target:**
* **LLVM IR:** A node representing the LLVM Intermediate Representation.
* **Target ISA:** A node representing the Target Instruction Set Architecture.
* Arrows connect ArmSME to LLVM IR, and LLVM IR to Target ISA.
5. **Additional Elements (Bottom-Left):**
* A black rectangle contains:
* **External Format:** A blue rounded rectangle.
* **Dialect:** A brown rounded rectangle.
* **Transform:** A red label.
6. **MLIR-based progressive lowering:**
* A vertical label on the right side of the diagram indicates the overall direction and purpose of the diagram.
### Key Observations
* The diagram illustrates a multi-stage compilation process, with C++ code being progressively lowered to target-specific instructions.
* The MLIR framework plays a central role, providing a flexible and extensible infrastructure for compiler optimization.
* Vectorization is a key optimization technique, with dedicated dialects and transformations.
* The feedback loop between ArmSME and Vector suggests iterative refinement of vector code.
### Interpretation
The diagram provides a high-level overview of a compiler optimization pipeline using MLIR. It demonstrates how code can be transformed through a series of intermediate representations and dialects, each tailored to specific optimization tasks. The use of vectorization and target-specific extensions (ArmSME) highlights the importance of leveraging hardware capabilities for performance. The "progressive lowering" approach allows for optimizations at different levels of abstraction, enabling a flexible and efficient compilation process. The "Raise" arrow between SCF and Affine suggests that these dialects can be interconverted, allowing for different optimization strategies to be applied. The "EnableArm Streaming" feedback loop suggests that the vectorization process can be iteratively refined based on target-specific constraints and performance characteristics.