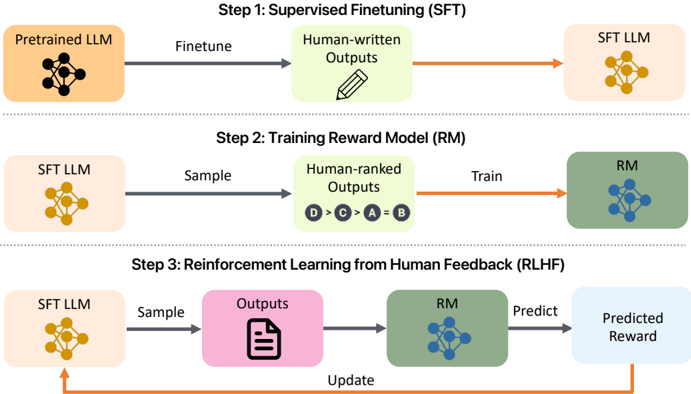
## Diagram: Reinforcement Learning from Human Feedback (RLHF) Process
### Overview
The image illustrates a three-step process for Reinforcement Learning from Human Feedback (RLHF). It outlines the steps of Supervised Finetuning (SFT), Training Reward Model (RM), and Reinforcement Learning from Human Feedback (RLHF). The diagram shows the flow of data and models between these steps, highlighting the role of human input in shaping the model's behavior.
### Components/Axes
* **Step 1: Supervised Finetuning (SFT)**
* **Pretrained LLM:** A light orange rounded rectangle containing a black neural network icon.
* **Finetune:** A grey arrow pointing from the Pretrained LLM to Human-written Outputs.
* **Human-written Outputs:** A light green rounded rectangle containing a pencil icon.
* **SFT LLM:** A light orange rounded rectangle containing a yellow neural network icon. An orange arrow points from Human-written Outputs to SFT LLM.
* **Step 2: Training Reward Model (RM)**
* **SFT LLM:** A light orange rounded rectangle containing a yellow neural network icon.
* **Sample:** A grey arrow pointing from the SFT LLM to Human-ranked Outputs.
* **Human-ranked Outputs:** A light green rounded rectangle containing the text "D > C > A = B" in circles.
* **RM:** A light green rounded rectangle containing a blue neural network icon.
* **Train:** An orange arrow pointing from Human-ranked Outputs to RM.
* **Step 3: Reinforcement Learning from Human Feedback (RLHF)**
* **SFT LLM:** A light orange rounded rectangle containing a yellow neural network icon.
* **Sample:** A grey arrow pointing from the SFT LLM to Outputs.
* **Outputs:** A light pink rounded rectangle containing a document icon.
* **RM:** A light green rounded rectangle containing a blue neural network icon.
* **Predict:** A grey arrow pointing from the RM to Predicted Reward.
* **Predicted Reward:** A light blue rounded rectangle.
* **Update:** An orange arrow pointing from Predicted Reward back to SFT LLM.
### Detailed Analysis or ### Content Details
The diagram is structured in three horizontal rows, each representing a step in the RLHF process.
* **Step 1: Supervised Finetuning (SFT)** involves taking a Pretrained LLM and finetuning it using Human-written Outputs to create an SFT LLM.
* **Step 2: Training Reward Model (RM)** uses the SFT LLM to sample outputs, which are then ranked by humans. This human-ranked data is used to train a Reward Model (RM). The ranking is represented as "D > C > A = B", indicating a preference order.
* **Step 3: Reinforcement Learning from Human Feedback (RLHF)** uses the SFT LLM to sample outputs, which are then evaluated by the RM to predict a reward. This predicted reward is used to update the SFT LLM, creating a feedback loop.
### Key Observations
* The diagram clearly shows the iterative nature of the RLHF process, with the output of each step feeding into the next.
* Human input is crucial in both the supervised finetuning and reward model training stages.
* The use of different colors for each component helps to visually distinguish the different stages and models.
### Interpretation
The diagram illustrates the RLHF process, which aims to align language models with human preferences. The process starts with a pre-trained language model, which is then fine-tuned using human-written data. This fine-tuned model is then used to generate outputs, which are ranked by humans. The human rankings are used to train a reward model, which is then used to provide feedback to the language model. This feedback loop allows the language model to learn to generate outputs that are more aligned with human preferences. The diagram highlights the importance of human feedback in the RLHF process.