\n
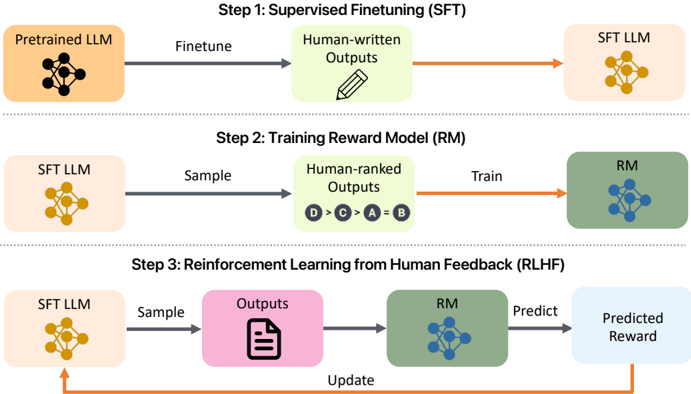
## Diagram: Reinforcement Learning from Human Feedback (RLHF) Process
### Overview
This diagram illustrates the three-step process of Reinforcement Learning from Human Feedback (RLHF) used to refine Large Language Models (LLMs). The process begins with Supervised Finetuning (SFT), moves to Training a Reward Model (RM), and concludes with Reinforcement Learning from Human Feedback (RLHF) itself. Each step involves a distinct flow of data and model updates.
### Components/Axes
The diagram is structured into three horizontal steps, each with input and output components. The steps are labeled:
1. Step 1: Supervised Finetuning (SFT)
2. Step 2: Training Reward Model (RM)
3. Step 3: Reinforcement Learning from Human Feedback (RLHF)
Key components include:
* **Pretrained LLM:** Represented by a yellow hexagonal network.
* **SFT LLM:** Represented by a yellow hexagonal network.
* **RM:** Represented by a teal hexagonal network.
* **Human-written Outputs:** Represented by a pencil icon.
* **Human-ranked Outputs:** Represented by a series of labeled circles (D > C > A = B).
* **Outputs:** Represented by a document icon.
* **Predicted Reward:** Represented by a light blue rounded rectangle.
Arrows indicate the flow of data and model updates. Labels on the arrows describe the process: "Finetune", "Sample", "Train", "Predict", "Update".
### Detailed Analysis or Content Details
**Step 1: Supervised Finetuning (SFT)**
* Input: Pretrained LLM (yellow hexagonal network).
* Process: Finetune.
* Output: SFT LLM (yellow hexagonal network).
**Step 2: Training Reward Model (RM)**
* Input: SFT LLM (yellow hexagonal network).
* Process: Sample -> Human-ranked Outputs (D > C > A = B) -> Train.
* Output: RM (teal hexagonal network).
* The human-ranked outputs are ordered as follows: D is best, C is next best, A and B are equal and lower ranked.
**Step 3: Reinforcement Learning from Human Feedback (RLHF)**
* Input: SFT LLM (yellow hexagonal network).
* Process: Sample -> Outputs (document icon) -> RM (teal hexagonal network) -> Predict -> Predicted Reward (light blue rounded rectangle) -> Update (arrow looping back to SFT LLM).
### Key Observations
The diagram highlights a cyclical process where the LLM is continuously refined based on human feedback. The RM acts as a bridge between the LLM's outputs and a quantifiable reward signal. The human ranking in Step 2 is crucial for training the RM to align with human preferences. The final step demonstrates a feedback loop where the LLM is updated based on the predicted reward from the RM.
### Interpretation
This diagram illustrates a common methodology for aligning LLMs with human values and preferences. The RLHF process addresses the limitations of purely supervised learning by incorporating human judgment into the training loop. The RM is a key component, as it learns to approximate human preferences and provides a reward signal that guides the LLM's learning. The cyclical nature of Step 3 suggests an iterative refinement process, where the LLM continuously improves its ability to generate outputs that are aligned with human expectations. The ranking system (D > C > A = B) in Step 2 provides a clear example of how human preferences are quantified and used to train the RM. The diagram doesn't provide specific data or numerical values, but rather a conceptual overview of the RLHF pipeline. It is a high-level representation of a complex process.