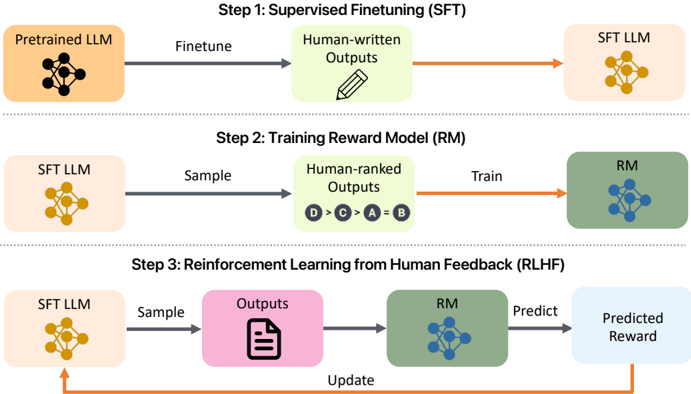
## Flowchart Diagram: Three-Stage Language Model Training Process
### Overview
The diagram illustrates a three-step iterative process for training a language model using human feedback. It combines supervised fine-tuning, reward model training, and reinforcement learning from human feedback (RLHF). The flow progresses from initial model adaptation to iterative improvement based on human evaluations.
### Components/Axes
**Legend (Bottom-Right):**
- **Orange**: Pretrained LLM, SFT LLM
- **Green**: Human-ranked Outputs, Reward Model (RM)
- **Blue**: Predicted Reward
- **Pink**: Outputs
- **Gray**: Arrows (Flow direction)
**Step 1: Supervised Finetuning (SFT)**
- **Components**:
- Pretrained LLM (orange)
- Human-written Outputs (green)
- SFT LLM (orange)
- **Flow**: Pretrained LLM → Finetune → Human-written Outputs → SFT LLM
**Step 2: Training Reward Model (RM)**
- **Components**:
- SFT LLM (orange)
- Human-ranked Outputs (green)
- Reward Model (RM) (green)
- **Flow**: SFT LLM → Sample → Human-ranked Outputs → Train → RM
**Step 3: Reinforcement Learning from Human Feedback (RLHF)**
- **Components**:
- SFT LLM (orange)
- Outputs (pink)
- Reward Model (RM) (green)
- Predicted Reward (blue)
- **Flow**: SFT LLM → Sample → Outputs → RM → Predicted Reward → Update
### Detailed Analysis
1. **Step 1 (SFT)**:
- A pretrained language model (LLM) is fine-tuned using human-written outputs to produce an SFT LLM.
- Color consistency: Orange nodes represent LLM variants, green represents human-generated outputs.
2. **Step 2 (RM Training)**:
- The SFT LLM generates outputs that are human-ranked (e.g., "D > C > A > B").
- These rankings train a reward model (RM) to evaluate outputs.
- Green nodes represent both human rankings and the trained RM.
3. **Step 3 (RLHF)**:
- The SFT LLM samples outputs, which are evaluated by the RM to predict rewards.
- The model is updated based on these predicted rewards, closing the feedback loop.
- Pink nodes represent raw outputs, blue nodes represent reward predictions.
### Key Observations
- **Iterative Process**: The diagram emphasizes cyclical improvement, with Step 3 feeding back into Step 1 via the "Update" arrow.
- **Color Consistency**: Orange dominates LLM components, green represents human input/RM, and blue/pink denote intermediate outputs/rewards.
- **Missing Metrics**: No numerical values or quantitative metrics are provided (e.g., accuracy, reward scores).
### Interpretation
This diagram outlines a standard RLHF pipeline for aligning language models with human preferences. The process begins with supervised adaptation (Step 1), progresses to reward modeling via human rankings (Step 2), and culminates in iterative refinement using predicted rewards (Step 3). The absence of quantitative data suggests this is a conceptual framework rather than an empirical study. The use of color-coding and directional arrows emphasizes modularity and feedback loops, critical for understanding how human input shapes model behavior over iterations.