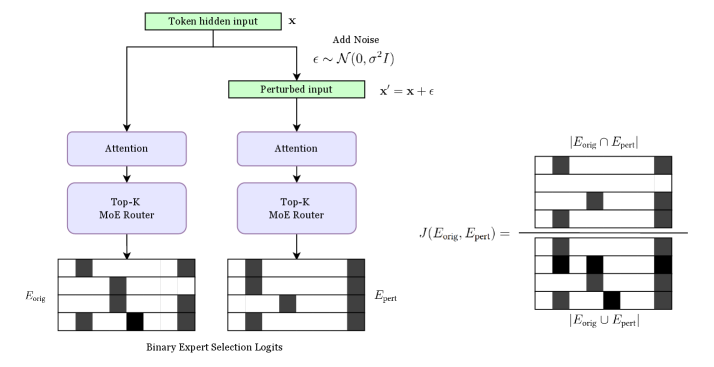
## Diagram: Model Architecture for Expert Selection with Perturbed Inputs
### Overview
The diagram illustrates a dual-path model architecture comparing original and perturbed input processing. It shows how token hidden inputs are processed through attention mechanisms and Top-K Mixture of Experts (MoE) routers to generate binary expert selection logits. A key component on the right quantifies the intersection of expert sets between original and perturbed inputs.
### Components/Axes
1. **Left Path (Original Input)**
- **Token hidden input (x)**: Starting point for original processing
- **Attention**: Processes input features
- **Top-K MoE Router**: Selects top-K experts
- **E_orig**: Binary expert selection logits for original input
2. **Right Path (Perturbed Input)**
- **Add Noise**: Introduces ε ~ N(0, σ²I) to input
- **Perturbed input (x' = x + ε)**: Modified input
- **Attention**: Processes perturbed features
- **Top-K MoE Router**: Selects top-K experts
- **E_pert**: Binary expert selection logits for perturbed input
3. **Intersection Metric**
- **Formula**: J(E_orig, E_pert) = |E_orig ∩ E_pert| / |E_orig ∪ E_pert|
- **Visualization**: Venn diagram showing overlap between expert sets
### Detailed Analysis
- **Input Processing**: Both paths use identical processing components (attention + MoE router), suggesting shared feature extraction mechanisms
- **Noise Injection**: Perturbed path introduces Gaussian noise (ε) with mean 0 and variance σ²I before processing
- **Expert Selection**: Binary logits (E_orig/E_pert) represent expert activation probabilities
- **Intersection Calculation**: J metric quantifies expert set overlap between original and perturbed inputs
### Key Observations
1. **Symmetric Architecture**: Both paths share identical processing components except for noise injection
2. **Expert Set Comparison**: The Venn diagram explicitly measures expert selection consistency
3. **Noise Impact**: The perturbation occurs before attention mechanisms, suggesting early feature space modification
4. **Binary Logits**: Expert selection uses binary (0/1) activation probabilities
### Interpretation
This architecture appears designed to:
1. **Test Robustness**: By comparing expert selection under original vs. perturbed inputs
2. **Quantify Sensitivity**: Through the J metric measuring expert set overlap
3. **Enable Adaptive Routing**: The MoE router suggests dynamic expert selection based on input characteristics
4. **Handle Uncertainty**: The noise injection (ε) introduces variability to test model stability
The diagram suggests a framework for evaluating how well expert selection mechanisms maintain consistency under input perturbations, which could be critical for applications requiring robustness to input variations or adversarial attacks.