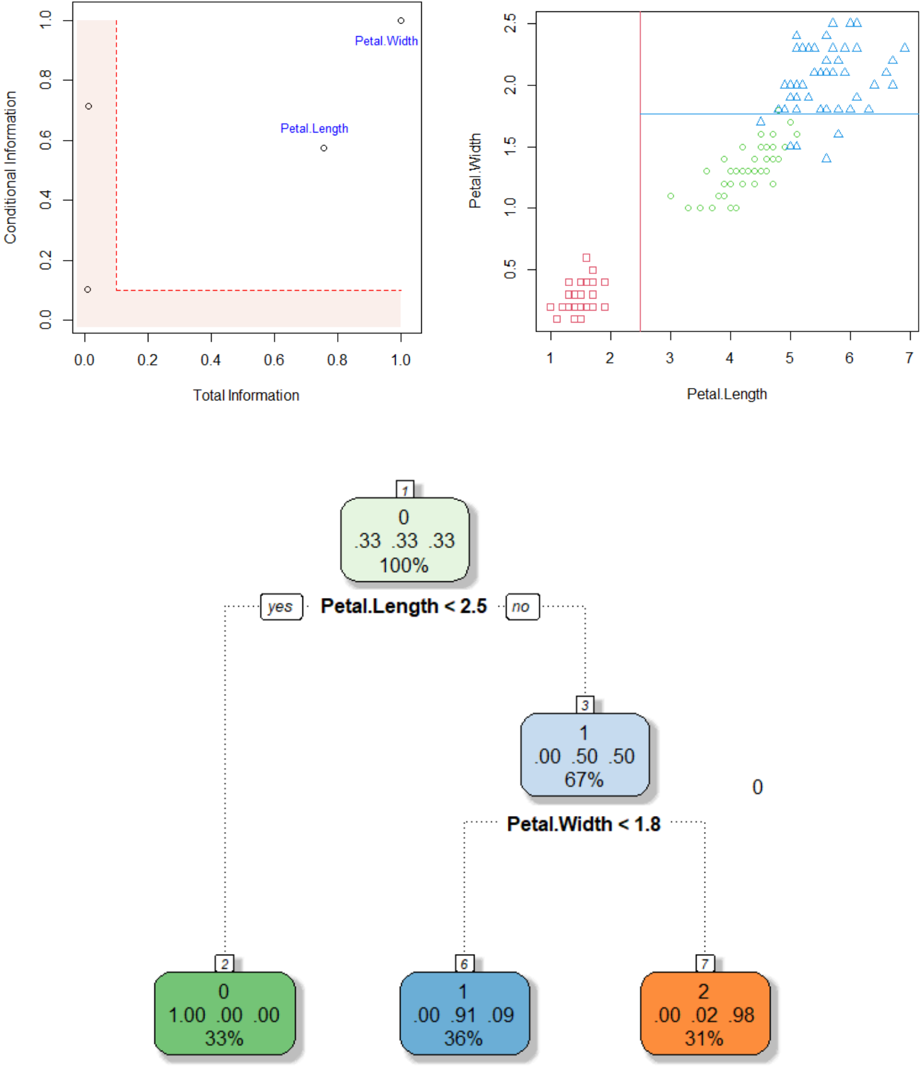
## Scatter Plots and Decision Tree: Iris Petal Measurements and Classification
### Overview
The image contains two scatter plots and a decision tree. The left scatter plot visualizes "Total Information" vs. "Conditional Information" with labeled data points. The right scatter plot shows "Petal Length" vs. "Petal Width" with color-coded shapes. The decision tree below classifies data based on petal measurements, with node values and split conditions.
---
### Components/Axes
#### Left Scatter Plot
- **X-axis**: Total Information (0.0–1.0)
- **Y-axis**: Conditional Information (0.0–1.0)
- **Data Points**:
- (0.1, 0.7): Labeled "Petal Width"
- (0.8, 0.6): Labeled "Petal Length"
- (0.9, 0.9): Labeled "Petal Width"
- **Shaded Area**: Light pink rectangle spanning (0,0) to (1,0.5)
- **Dashed Line**: Red dashed line at y=0.5 (Conditional Information threshold)
#### Right Scatter Plot
- **X-axis**: Petal Length (1–7)
- **Y-axis**: Petal Width (0–2.5)
- **Data Points**:
- **Red Squares**: Clustered near (1–2, 0–1)
- **Blue Triangles**: Spread across (4–7, 1.5–2.5)
- **Green Circles**: Distributed between (3–5, 0.5–1.5)
- **Dashed Lines**:
- Vertical red line at x=3 (Petal Length threshold)
- Horizontal blue line at y=1.5 (Petal Width threshold)
- **Legend**: Top-right, associating colors with shapes (red=squares, blue=triangles, green=circles)
#### Decision Tree
- **Root Node (1)**:
- Condition: `Petal.Length < 2.5`
- Yes → Node 2 (green)
- No → Node 3 (blue)
- **Node 2**:
- Values: `[0, 33, 33, 33]`
- Percentage: 100%
- **Node 3**:
- Condition: `Petal.Width < 1.8`
- Yes → Node 6 (blue)
- No → Node 7 (orange)
- **Leaf Nodes**:
- Node 6: `[1, 0.00, 0.91, 0.09]`, 36%
- Node 7: `[2, 0.00, 0.02, 0.98]`, 31%
---
### Detailed Analysis
#### Left Scatter Plot
- **Trends**:
- Petal Width (0.1, 0.7) and Petal Length (0.8, 0.6) show high conditional information.
- Petal Width (0.9, 0.9) lies near the upper-right corner, suggesting maximum conditional information.
- **Shaded Area**: Indicates a region where conditional information is ≤0.5. Only Petal Length (0.8, 0.6) partially overlaps this area.
#### Right Scatter Plot
- **Trends**:
- **Red Squares**: Low petal length (1–2) and width (0–1), likely representing a specific class (e.g., Setosa).
- **Blue Triangles**: High petal length (4–7) and width (1.5–2.5), possibly Virginica.
- **Green Circles**: Intermediate values (3–5, 0.5–1.5), likely Versicolor.
- **Dashed Lines**: Thresholds at Petal Length=3 and Width=1.5 align with class separations.
#### Decision Tree
- **Splits**:
- Root splits on `Petal.Length < 2.5` (100% accuracy for Node 2).
- Node 3 splits on `Petal.Width < 1.8`, with 67% accuracy for Node 6 and 31% for Node 7.
- **Node Values**:
- Node 2: All values = 33 (100% confidence in a single class).
- Node 6: 1 instance of class 0, 91% class 1, 9% class 2.
- Node 7: 2 instances of class 0, 2% class 1, 98% class 2.
---
### Key Observations
1. **Feature Importance**: Petal Width has higher conditional information than Petal Length in the left plot.
2. **Class Separation**: The right plot shows distinct clusters for red squares (low length/width), blue triangles (high length/width), and green circles (intermediate).
3. **Decision Tree Logic**:
- Petal Length < 2.5 perfectly separates one class (Node 2).
- Petal Width < 1.8 further splits remaining data, with higher accuracy for shorter widths (Node 6).
---
### Interpretation
- **Data Relationships**:
- The left plot quantifies feature importance, showing Petal Width as more informative.
- The right plot visualizes class distributions, with clear separations along petal length and width.
- **Model Behavior**:
- The decision tree prioritizes Petal Length first, then Petal Width, reflecting their importance.
- Node 2’s 100% accuracy suggests a strong class boundary at Petal.Length < 2.5.
- **Anomalies**:
- Petal Width (0.9, 0.9) in the left plot has the highest conditional information, indicating it may be a critical feature for distinguishing classes.
- Node 7’s low accuracy (31%) suggests uncertainty in classifying samples with Petal.Length ≥2.5 and Width ≥1.8.
This analysis demonstrates how petal measurements correlate with classification confidence and how the decision tree leverages these features for prediction.