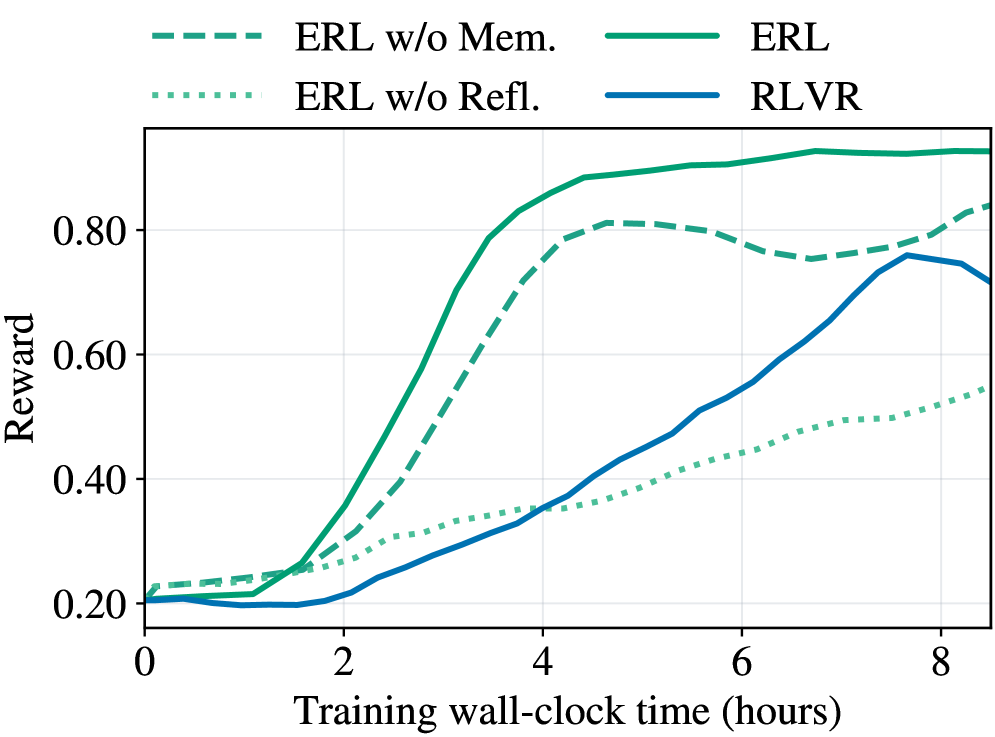
\n
## Line Chart: Reward vs. Training Time for Reinforcement Learning Algorithms
### Overview
This line chart depicts the relationship between reward and training wall-clock time for four different reinforcement learning algorithms: ERL w/o Mem., ERL, ERL w/o Refl., and RLVR. The chart shows how the reward obtained by each algorithm changes as the training time increases.
### Components/Axes
* **X-axis:** Training wall-clock time (hours), ranging from 0 to 8 hours.
* **Y-axis:** Reward, ranging from 0.20 to 0.90.
* **Legend:** Located at the top-center of the chart, identifying each line with a specific color and label:
* ERL w/o Mem. (dashed light blue)
* ERL (solid teal)
* ERL w/o Refl. (dotted green)
* RLVR (solid dark blue)
### Detailed Analysis
* **ERL w/o Mem. (dashed light blue):** This line starts at approximately 0.22 at 0 hours, increases rapidly to around 0.85 by 4 hours, plateaus around 0.82-0.85 between 4 and 7 hours, and then decreases slightly to approximately 0.78 at 8 hours.
* **ERL (solid teal):** This line begins at approximately 0.21 at 0 hours, increases steadily to around 0.75 by 4 hours, continues to increase to approximately 0.78 by 7 hours, and then remains relatively stable at around 0.77-0.78 at 8 hours.
* **ERL w/o Refl. (dotted green):** This line starts at approximately 0.23 at 0 hours, increases gradually to around 0.50 by 4 hours, continues to increase to approximately 0.58 by 8 hours.
* **RLVR (solid dark blue):** This line begins at approximately 0.20 at 0 hours, increases steadily to around 0.55 by 4 hours, continues to increase to approximately 0.68 by 8 hours.
### Key Observations
* ERL w/o Mem. achieves the highest reward values, particularly between 4 and 7 hours, but experiences a slight decline at 8 hours.
* ERL consistently outperforms RLVR and ERL w/o Refl. throughout the entire training period.
* ERL w/o Refl. exhibits the slowest reward increase and remains the lowest performing algorithm.
* RLVR shows a steady increase in reward, but lags behind ERL and ERL w/o Mem.
### Interpretation
The data suggests that incorporating memory into the ERL algorithm (ERL w/o Mem.) significantly improves performance, as evidenced by the higher reward values achieved. However, the slight decline in reward at 8 hours for ERL w/o Mem. could indicate overfitting or a need for further refinement. The ERL algorithm, while not as high-performing as ERL w/o Mem., still demonstrates a consistent and positive trend. Removing reflection (ERL w/o Refl.) appears to hinder the learning process, resulting in the lowest reward values. RLVR shows a reasonable learning curve, but is consistently outperformed by the ERL variants. The chart highlights the importance of memory and reflection in the ERL algorithm for achieving optimal performance in this reinforcement learning task. The plateauing of ERL w/o Mem. suggests diminishing returns from continued training, while the continued increase of other algorithms indicates they may benefit from longer training times.