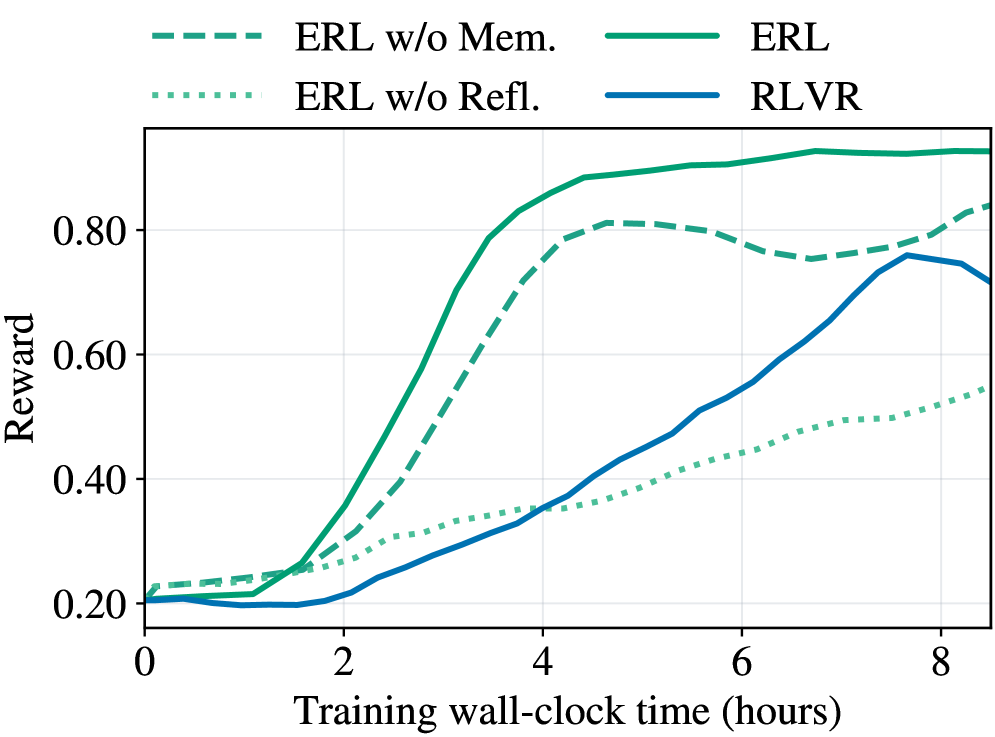
## Line Graph: Reward vs. Training Wall-Clock Time for Reinforcement Learning Models
### Overview
The image is a line graph comparing the performance of four reinforcement learning (RL) models over training time (0–8 hours). The y-axis measures "Reward" (0.2–0.8), and the x-axis represents "Training wall-clock time (hours)". Four lines are plotted, differentiated by color and style, with a legend in the top-left corner.
### Components/Axes
- **X-axis**: "Training wall-clock time (hours)" with ticks at 0, 2, 4, 6, and 8.
- **Y-axis**: "Reward" with ticks at 0.2, 0.4, 0.6, and 0.8.
- **Legend**: Located in the top-left, with four entries:
- **Solid green**: ERL (full model)
- **Dashed green**: ERL w/o Mem. (no memory)
- **Dotted green**: ERL w/o Refl. (no reflection)
- **Solid blue**: RLVR (baseline model)
### Detailed Analysis
1. **ERL (Solid Green)**:
- Starts at ~0.2 reward at 0 hours.
- Rises sharply to ~0.85 by 6 hours, then plateaus.
- Exceeds the y-axis maximum (0.8), suggesting a value slightly above 0.8.
2. **ERL w/o Mem. (Dashed Green)**:
- Begins at ~0.2, rises to ~0.8 by 4 hours.
- Dips slightly to ~0.75 by 8 hours, indicating instability after initial gains.
3. **ERL w/o Refl. (Dotted Green)**:
- Starts at ~0.2, rises slowly to ~0.55 by 8 hours.
- Shows the least improvement over time.
4. **RLVR (Solid Blue)**:
- Begins at ~0.2, increases steadily to ~0.75 by 8 hours.
- Maintains a consistent upward trend without plateaus.
### Key Observations
- **ERL** achieves the highest reward (~0.85) but plateaus after 6 hours.
- **ERL w/o Mem.** underperforms after 4 hours, dropping to ~0.75 by 8 hours.
- **ERL w/o Refl.** has the slowest growth, reaching only ~0.55 by 8 hours.
- **RLVR** performs consistently but lags behind ERL in peak reward.
### Interpretation
The graph demonstrates that the full ERL model (with memory and reflection) outperforms variants missing either component. The sharp rise of ERL suggests memory and reflection are critical for rapid learning. Removing memory causes a performance drop after initial gains, implying memory aids long-term retention. The absence of reflection results in slower improvement, highlighting its role in refining strategies. RLVR serves as a stable baseline but does not match ERL's peak performance. This indicates that ERL's architecture, integrating memory and reflection, is essential for maximizing reward in training scenarios. The plateau in ERL's performance after 6 hours may suggest diminishing returns or convergence to an optimal policy.