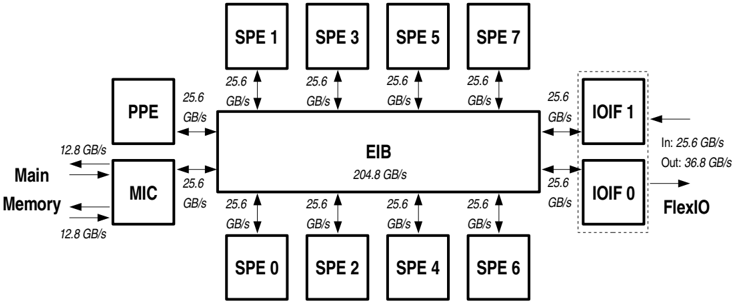
## Block Diagram: Cell Broadband Engine Architecture
### Overview
The image is a block diagram illustrating the architecture of the Cell Broadband Engine, focusing on the data transfer rates between its components. It shows the main processing elements (SPEs, PPE, MIC), the Element Interconnect Bus (EIB), and the I/O interfaces (IOIFs). Data transfer rates are indicated in GB/s.
### Components/Axes
* **Main Memory:** Located on the left side of the diagram.
* **MIC:** Located below the PPE on the left side.
* **PPE:** Located above the MIC on the left side.
* **SPEs:** Eight SPEs are arranged around the EIB, labeled SPE 0, SPE 1, SPE 2, SPE 3, SPE 4, SPE 5, SPE 6, and SPE 7.
* **EIB (Element Interconnect Bus):** Located in the center of the diagram.
* **IOIFs:** Two I/O Interface units, IOIF 0 and IOIF 1, are located on the right side, enclosed in a dashed box labeled "FlexIO".
* **Data Transfer Rates:** Indicated in GB/s along the arrows connecting the components.
### Detailed Analysis or ### Content Details
* **Main Memory:** Data transfer rate to/from MIC is 12.8 GB/s in both directions.
* **MIC:** Data transfer rate to/from EIB is 25.6 GB/s in both directions.
* **PPE:** Data transfer rate to/from EIB is 25.6 GB/s in both directions.
* **SPEs:** Each SPE (0-7) has a data transfer rate of 25.6 GB/s to/from the EIB.
* **EIB:** Total bandwidth is 204.8 GB/s.
* **IOIF 0 & IOIF 1:** Data transfer rate to/from EIB is 25.6 GB/s in both directions.
* **FlexIO:** Input to IOIF 1 is 25.6 GB/s. Output from IOIF 0 is 36.8 GB/s.
### Key Observations
* The EIB serves as the central hub for data transfer between all components.
* The SPEs have identical data transfer rates to the EIB.
* The FlexIO interface has different input and output data transfer rates.
* The Main Memory has a lower data transfer rate compared to other components.
### Interpretation
The diagram illustrates the high-bandwidth, interconnected architecture of the Cell Broadband Engine. The EIB's high bandwidth (204.8 GB/s) is crucial for enabling efficient data transfer between the various processing elements (SPEs, PPE) and I/O interfaces. The lower data transfer rate between the Main Memory and MIC suggests a potential bottleneck in memory access. The difference in input and output rates for the FlexIO interface indicates an asymmetry in I/O operations, possibly optimized for specific data flow patterns. The architecture is designed for parallel processing, with multiple SPEs capable of simultaneously accessing the EIB.