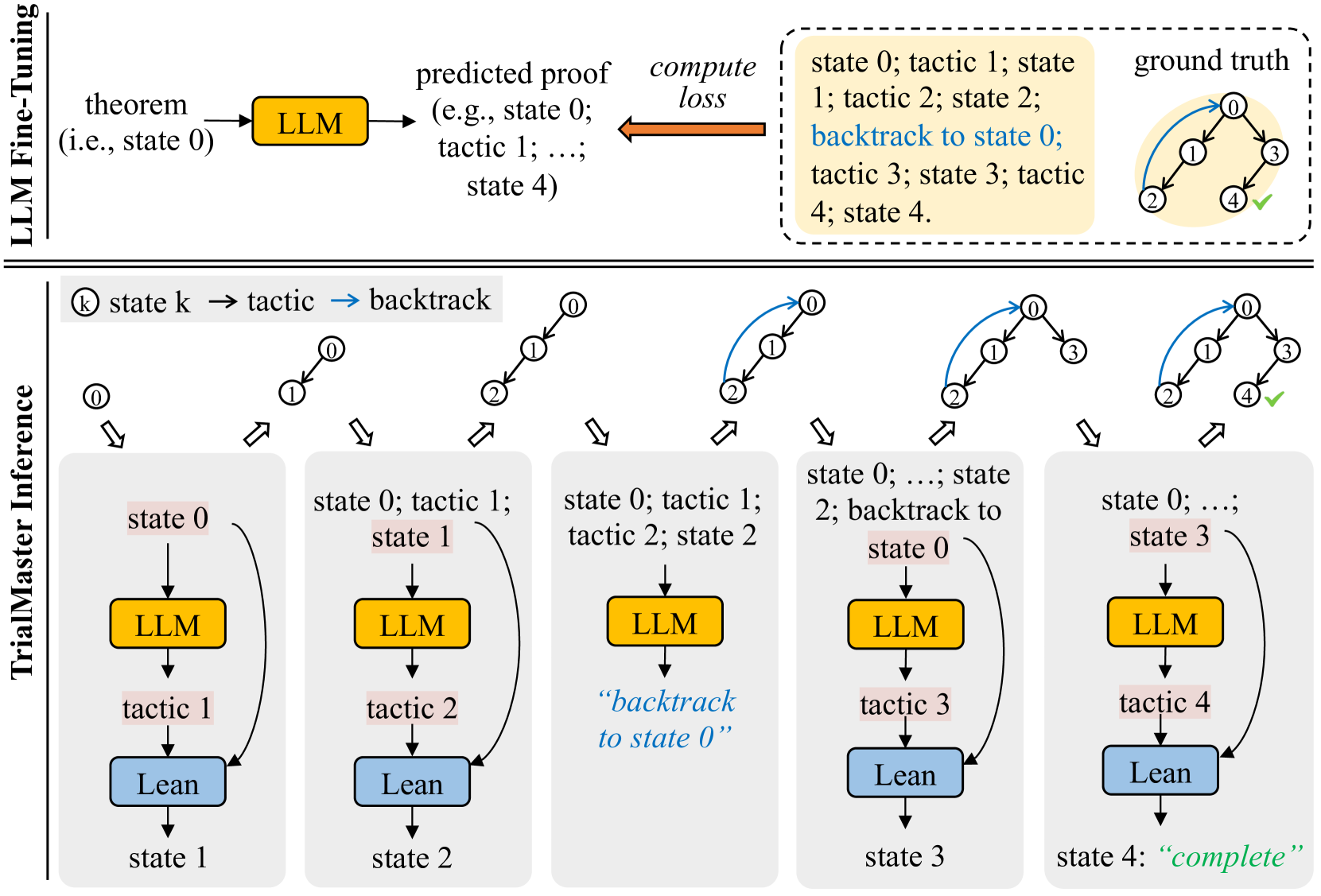
## Diagram: LLM Fine-Tuning and TrialMaster Inference
### Overview
The image illustrates a process involving LLM (Large Language Model) fine-tuning and TrialMaster inference for theorem proving. It shows the flow from a theorem to a predicted proof using an LLM, the computation of loss, and a comparison with the ground truth. The TrialMaster inference section details the iterative process of applying tactics and backtracking to find a complete proof.
### Components/Axes
* **Title**: LLM Fine-Tuning (top-left)
* **Title**: TrialMaster Inference (left)
* **Nodes**:
* Theorem (i.e., state 0)
* LLM (yellow box)
* Predicted proof (e.g., state 0; tactic 1; ...; state 4)
* Compute loss (orange arrow)
* Ground truth (tree structure with nodes labeled 0, 1, 2, 3, 4, and a green checkmark on node 4)
* State k (node in the inference process)
* Tactic (action applied to a state)
* Backtrack (blue arrow indicating a return to a previous state)
* Lean (blue box)
* **States**: State 0, State 1, State 2, State 3, State 4
* **Tactics**: Tactic 1, Tactic 2, Tactic 3, Tactic 4
* **Legend**: Located at the top-center, showing:
* (k) state k -> tactic -> backtrack (blue arrow)
### Detailed Analysis
The diagram is divided into two main sections: LLM Fine-Tuning (top) and TrialMaster Inference (bottom).
**LLM Fine-Tuning:**
1. **Input**: A theorem (i.e., state 0) is fed into the LLM (yellow box).
2. **Process**: The LLM generates a predicted proof, which is a sequence of states and tactics (e.g., state 0; tactic 1; ...; state 4).
3. **Evaluation**: The predicted proof is compared to the ground truth, and a loss is computed. The ground truth is represented as a tree structure with nodes 0, 1, 2, 3, and 4, where node 4 has a green checkmark, indicating a successful proof. The ground truth also shows a blue arrow indicating a backtrack from node 2 to node 0.
4. **Text Box**: A text box on the top-right contains the sequence of states and tactics: "state 0; tactic 1; state 1; tactic 2; state 2; backtrack to state 0; tactic 3; state 3; tactic 4; state 4."
**TrialMaster Inference:**
This section shows the iterative process of theorem proving using the LLM. It consists of five stages, each representing a step in the inference process.
* **Stage 1**:
* Initial state: state 0 (highlighted in light red)
* LLM generates tactic 1 (yellow box)
* Lean applies tactic 1, resulting in state 1 (blue box)
* **Stage 2**:
* Initial state: state 0; tactic 1; state 1 (state 1 highlighted in light red)
* LLM generates tactic 2 (yellow box)
* Lean applies tactic 2, resulting in state 2 (blue box)
* **Stage 3**:
* Initial state: state 0; tactic 1; tactic 2; state 2 (state 0 highlighted in light red)
* LLM generates tactic 3 (yellow box)
* The text "backtrack to state 0" is displayed in blue.
* Lean applies tactic 3, resulting in state 3 (blue box)
* **Stage 4**:
* Initial state: state 0; ...; state 2; backtrack to state 0 (state 3 highlighted in light red)
* LLM generates tactic 4 (yellow box)
* Lean applies tactic 4, resulting in state 4 (blue box)
* **Stage 5**:
* Initial state: state 0; ...; state 3 (state 4 highlighted in light red)
* The process reaches state 4, which is marked as "complete" in green.
Each stage starts with a tree-like diagram showing the current state of the proof. The nodes are numbered, and blue arrows indicate backtracking.
### Key Observations
* The LLM is used to generate tactics based on the current state of the proof.
* The Lean theorem prover applies the tactics to transition between states.
* Backtracking is used to explore different paths in the proof search.
* The process continues until a complete proof is found (state 4).
### Interpretation
The diagram illustrates a system for automated theorem proving that combines the strengths of large language models (LLMs) and formal theorem provers like Lean. The LLM is used to suggest tactics, while Lean ensures the correctness of the proof steps. The TrialMaster inference process demonstrates how the system iteratively explores the search space, using backtracking to recover from dead ends. The comparison with the ground truth in the LLM Fine-Tuning section suggests that the LLM is trained to generate proofs that align with known solutions. The diagram highlights the importance of both prediction (LLM) and verification (Lean) in automated theorem proving.