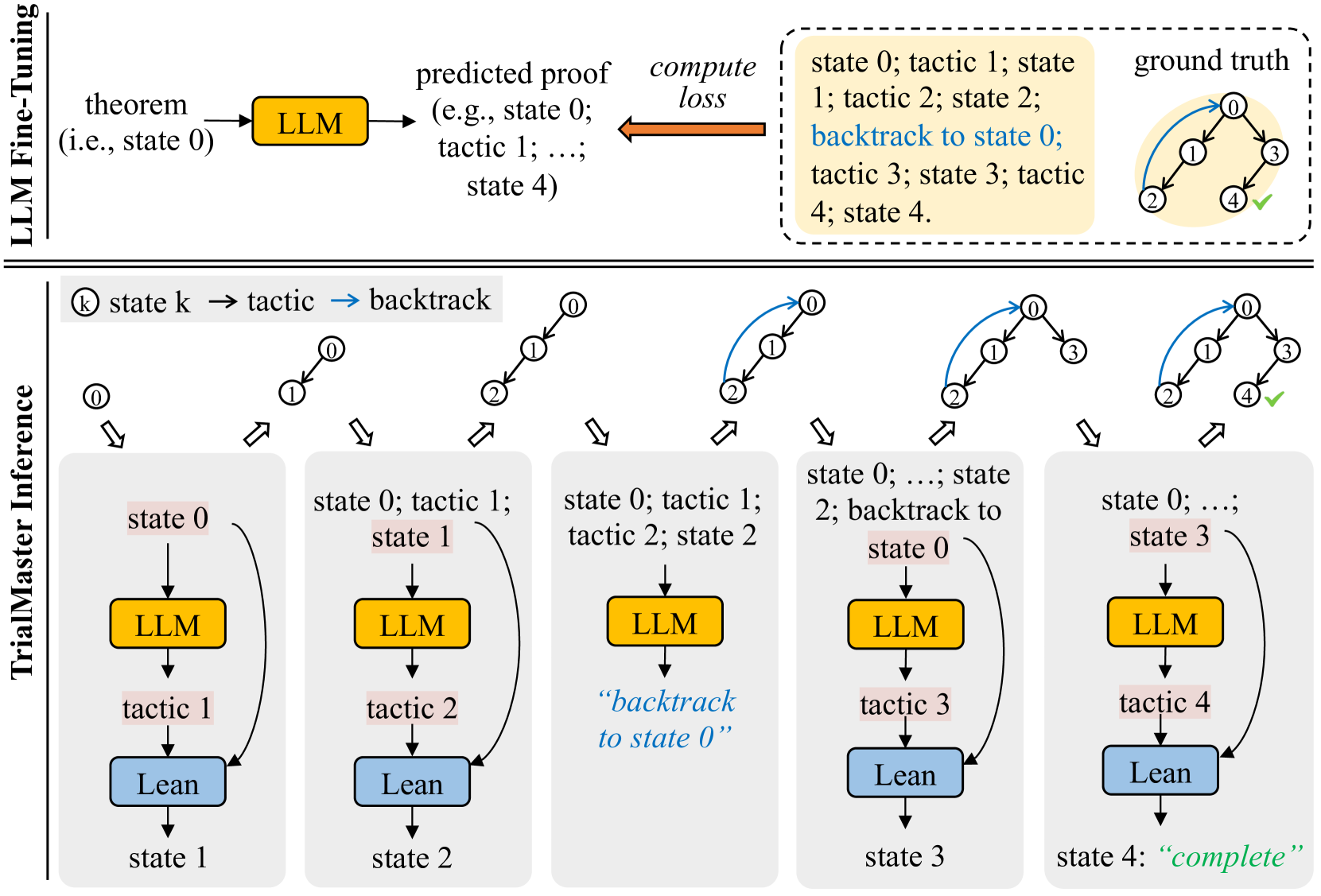
## Diagram: LLM Fine-Tuning and TrialMaster Inference
### Overview
This diagram illustrates the process of LLM (Large Language Model) fine-tuning and subsequent TrialMaster inference for theorem proving. The upper section depicts the fine-tuning process, while the lower section details the inference stage. The diagram uses a series of state transitions and tactics to represent the progression of the proof search.
### Components/Axes
The diagram is divided into two main sections separated by a dashed line: "LLM Fine-Tuning" and "TrialMaster Inference".
**LLM Fine-Tuning Section:**
* **Input:** "theorem (i.e. state 0)"
* **Process:** LLM -> "predicted proof (e.g. state 0; tactic 1; ...; state 4)" -> "compute loss"
* **Output:** "state 0; tactic 1; state 1; tactic 2; state 2; backtrack to state 0; tactic 3; state 3; tactic 4; state 4"
* **Ground Truth:** A circular diagram with nodes 0-4 and a green checkmark on node 4.
**TrialMaster Inference Section:**
* **States:** state 0, state 1, state 2, state 3, state 4 ("complete")
* **Tactics:** tactic 1, tactic 2, tactic 3, tactic 4
* **Backtrack:** Indicated by a double-headed arrow.
* **Components:** LLM (pink rectangle), Lean (green rectangle)
### Detailed Analysis or Content Details
**LLM Fine-Tuning:**
The process begins with a "theorem" (initial state 0). This theorem is fed into an LLM, which predicts a proof sequence represented as a series of states and tactics. A loss is computed based on the predicted proof, and the LLM is updated accordingly. The predicted proof sequence is: state 0, tactic 1, state 1, tactic 2, state 2, backtrack to state 0, tactic 3, state 3, tactic 4, state 4. The "ground truth" shows a successful proof reaching state 4, indicated by a green checkmark.
**TrialMaster Inference:**
This section shows a sequence of states and tactics applied by the LLM and Lean.
* **Step 1:** State 0. LLM proposes tactic 1. Lean applies tactic 1, transitioning to state 1.
* **Step 2:** State 1. LLM proposes tactic 2. Lean applies tactic 2, transitioning to state 2.
* **Step 3:** State 2. LLM proposes a backtrack to state 0.
* **Step 4:** State 0. LLM proposes tactic 3. Lean applies tactic 3, transitioning to state 3.
* **Step 5:** State 3. LLM proposes tactic 4. Lean applies tactic 4, transitioning to state 4 ("complete").
The arrows indicate the flow of the proof search. Double-headed arrows represent backtracking. The circular diagrams above each state show the current state of the proof.
### Key Observations
* The fine-tuning process aims to align the LLM's predicted proof sequence with the ground truth.
* The TrialMaster inference process involves iterative application of tactics by the LLM, followed by execution by Lean.
* Backtracking is a crucial component of the proof search, allowing the system to explore alternative paths.
* The final state 4 is labeled "complete", indicating a successful proof.
* The diagram highlights the interplay between the LLM (generating tactics) and Lean (executing tactics).
### Interpretation
The diagram illustrates a reinforcement learning-like approach to theorem proving. The LLM is fine-tuned to predict effective proof tactics, and the TrialMaster inference process uses these predictions to navigate the proof search space. The "compute loss" step in the fine-tuning section suggests that the LLM is being trained to minimize the difference between its predicted proof sequence and the ground truth. The backtracking mechanism allows the system to recover from incorrect tactic applications and explore alternative proof paths. The successful completion of the proof in state 4 demonstrates the effectiveness of this approach. The diagram suggests a system where the LLM acts as a high-level strategist, proposing tactics, while Lean serves as a low-level executor, verifying and applying those tactics. The cyclical nature of the TrialMaster inference process, with its potential for backtracking, reflects the iterative and exploratory nature of theorem proving.