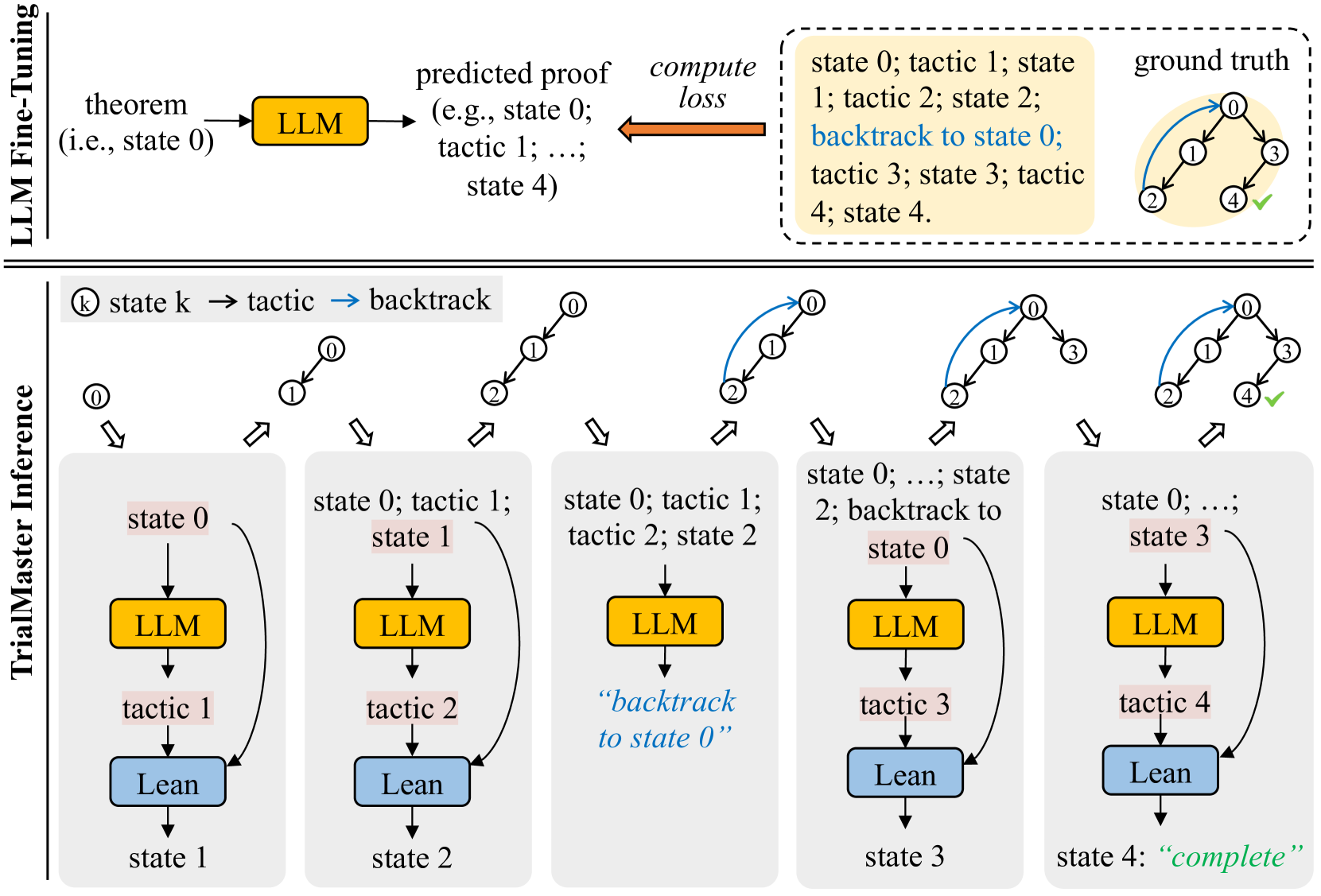
## Diagram: LLM Fine-Tuning and TrialMaster Inference Process
### Overview
The diagram illustrates a two-phase process for training and deploying a Large Language Model (LLM) in a formal proof or theorem-proving context. The top section details **LLM Fine-Tuning**, while the bottom section outlines **TrialMaster Inference**, a step-by-step execution framework with error correction.
---
### Components/Axes
#### LLM Fine-Tuning (Top Section)
- **Input**: Theorem (e.g., "state 0").
- **LLM Block**: Processes the theorem to generate a **predicted proof** (e.g., "state 0; tactic 1; ...; state 4").
- **Compute Loss**: Compares the predicted proof to the **ground truth** (a correct sequence of states and tactics).
- **Ground Truth**: Visualized as a cyclic path (0 → 1 → 2 → 3 → 4 → 0) with verified correctness (✓).
#### TrialMaster Inference (Bottom Section)
- **States**: Sequential steps (state 0 → state 1 → ... → state 4).
- **Components**:
- **LLM**: Yellow blocks generating outputs.
- **Lean**: Blue blocks executing tactics (e.g., "tactic 1", "tactic 2").
- **Flow**:
- **Forward Execution**: State 0 → tactic 1 → state 1 → ... → state 3 → tactic 4 → state 4 ("complete").
- **Backtracking**: State 2 includes a loop back to state 0 ("backtrack to state 0").
---
### Detailed Analysis
#### LLM Fine-Tuning
1. **Input**: A theorem (e.g., "state 0") is fed into the LLM.
2. **Output**: The LLM predicts a proof sequence (e.g., "state 0; tactic 1; ...; state 4").
3. **Loss Calculation**: The predicted proof is compared to the ground truth to compute loss, guiding model adjustments.
#### TrialMaster Inference
1. **State 0**: Initial state with LLM and Lean.
2. **State 1**: LLM generates "tactic 1", Lean executes it, transitioning to state 1.
3. **State 2**: LLM generates "tactic 2", Lean executes it, transitioning to state 2. A backtracking arrow loops back to state 0.
4. **State 3**: LLM generates "tactic 3", Lean executes it, transitioning to state 3.
5. **State 4**: LLM generates "tactic 4", Lean executes it, marking the process as "complete".
---
### Key Observations
1. **Backtracking Mechanism**: State 2 explicitly includes a loop to state 0, suggesting error recovery or exploration of alternative proof paths.
2. **Cyclic Ground Truth**: The ground truth forms a closed loop (0 → 1 → 2 → 3 → 4 → 0), implying iterative refinement.
3. **Component Roles**:
- **LLM**: Proposes proof steps.
- **Lean**: Executes tactics and validates transitions.
4. **State 4**: Labeled "complete", indicating successful termination of the inference process.
---
### Interpretation
This diagram represents a hybrid system for formal reasoning:
1. **Training Phase (LLM Fine-Tuning)**:
- The LLM is trained to generate proofs by minimizing the discrepancy between its predictions and the ground truth.
- The ground truth’s cyclic nature suggests the model learns to handle iterative or recursive proofs.
2. **Inference Phase (TrialMaster)**:
- The system executes proofs step-by-step, with Lean validating each tactic’s correctness.
- Backtracking in state 2 implies the system can abandon invalid paths and restart, enhancing robustness.
- The "complete" state in step 4 signifies successful proof completion, likely after resolving all subgoals.
3. **Design Implications**:
- The integration of LLM (generative) and Lean (verificational) creates a closed-loop system for automated theorem proving.
- Backtracking introduces a form of search or exploration, critical for handling complex or ambiguous proofs.
---
### Notes
- **Language**: All text is in English.
- **No Numerical Data**: The diagram focuses on process flow rather than quantitative metrics.
- **Color Coding**: Yellow (LLM) and blue (Lean) blocks visually distinguish components.