\n
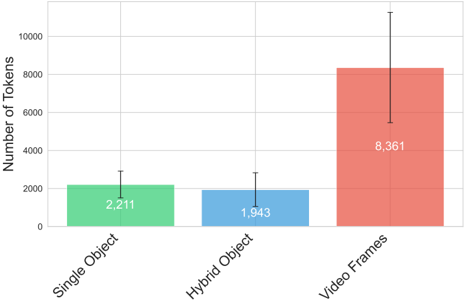
## Bar Chart: Number of Tokens by Object Type
### Overview
The image presents a bar chart comparing the number of tokens generated for three different object types: Single Object, Hybrid Object, and Video Frames. Each bar also includes an error bar indicating variability.
### Components/Axes
* **X-axis:** Object Type (Single Object, Hybrid Object, Video Frames)
* **Y-axis:** Number of Tokens (Scale from 0 to 10000, increments of 2000)
* **Bars:** Represent the average number of tokens for each object type.
* Single Object: Green
* Hybrid Object: Blue
* Video Frames: Red
* **Error Bars:** Black vertical lines extending above and below each bar, indicating the standard deviation or confidence interval.
### Detailed Analysis
* **Single Object:** The green bar represents approximately 2,211 tokens. The error bar extends from roughly 1,800 to 2,600 tokens.
* **Hybrid Object:** The blue bar represents approximately 1,943 tokens. The error bar extends from roughly 1,500 to 2,300 tokens.
* **Video Frames:** The red bar represents approximately 8,361 tokens. The error bar extends from roughly 7,500 to 9,200 tokens.
The bars are positioned horizontally along the x-axis, with "Single Object" on the left, "Hybrid Object" in the center, and "Video Frames" on the right. The values are displayed directly above each bar.
### Key Observations
* Video Frames generate significantly more tokens than Single Objects or Hybrid Objects.
* The number of tokens for Single Objects and Hybrid Objects are relatively similar.
* The error bar for Video Frames is larger than the error bars for Single Objects and Hybrid Objects, suggesting greater variability in the number of tokens generated for video frames.
### Interpretation
The data suggests that processing video frames requires significantly more tokenization than processing single or hybrid objects. This could be due to the increased complexity of video data, including both spatial and temporal information. The larger error bar for video frames might indicate that the number of tokens generated varies more depending on the content of the video. This information could be useful in optimizing tokenization strategies for different types of data, or in estimating the computational resources required for processing video data. The difference in token count could also be related to the amount of information contained within each data type. Video frames, being a sequence of images, inherently contain more information than a single object or a hybrid object.