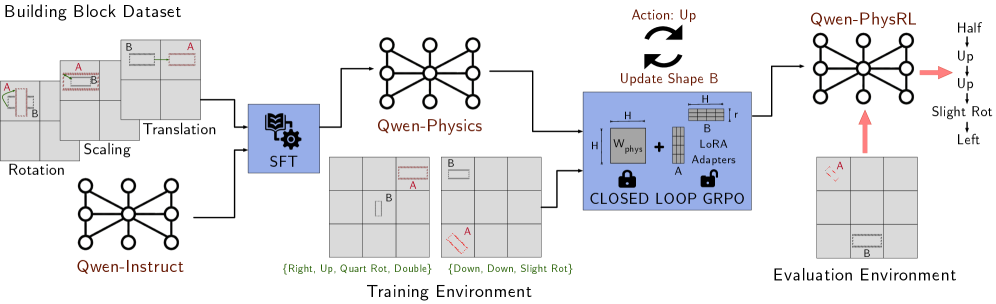
## Diagram: Building Block Dataset Workflow
### Overview
The image is a diagram illustrating a workflow for a building block dataset, likely used in a machine learning or AI context. It shows the process from initial data transformations to training and evaluation environments, incorporating components like Qwen-Instruct, Qwen-Physics, and a closed-loop GRPO.
### Components/Axes
* **Title:** Building Block Dataset
* **Initial Transformations (Left):**
* Rotation: Shows a 3x3 grid with blocks A and B undergoing rotation.
* Scaling: Shows a 3x3 grid with blocks A and B undergoing scaling.
* Translation: Shows a 3x3 grid with blocks A and B undergoing translation.
* **Qwen-Instruct:** A network diagram labeled "Qwen-Instruct" below the initial transformations.
* **SFT:** A blue box containing a book and gear icon, labeled "SFT".
* **Qwen-Physics:** A network diagram labeled "Qwen-Physics".
* **Training Environment:**
* Two 3x3 grids showing different block configurations.
* Text below the grids: "{Right, Up, Quart Rot, Double} {Down, Down, Slight Rot}"
* **Closed Loop GRPO:** A blue box labeled "CLOSED LOOP GRPO" containing:
* Wphys: A square labeled "Wphys" with height and width indicated by "H".
* LoRA Adapters: A stack of blocks labeled "LoRA Adapters" with height "H" and width "r".
* "+" symbol between Wphys and LoRA Adapters.
* Padlock icons above "CLOSED LOOP GRPO"
* "Update Shape B" above the box, with a circular arrow indicating feedback.
* "Action: Up" above the circular arrow.
* **Qwen-PhysRL:** A network diagram labeled "Qwen-PhysRL".
* **Evaluation Environment:** A 3x3 grid showing blocks A and B.
* **Action Labels (Right of Qwen-PhysRL):**
* Half
* Up
* Up
* Slight Rot
* Left
### Detailed Analysis
1. **Data Flow:** The workflow starts with initial transformations (Rotation, Scaling, Translation) applied to building blocks.
2. **Qwen-Instruct:** This component feeds into the SFT (likely Supervised Fine-Tuning) module.
3. **SFT and Qwen-Physics:** The output of SFT is processed by Qwen-Physics.
4. **Training Environment:** The training environment provides data for the Closed Loop GRPO.
5. **Closed Loop GRPO:** This module updates the shape B based on actions, creating a feedback loop. It combines Wphys and LoRA Adapters.
6. **Qwen-PhysRL and Evaluation:** The output of the GRPO is fed into Qwen-PhysRL, which interacts with the Evaluation Environment.
7. **Action Labels:** The actions "Half", "Up", "Up", "Slight Rot", and "Left" are associated with the Qwen-PhysRL component, indicating possible actions or outputs.
### Key Observations
* The diagram illustrates a closed-loop system for training and evaluating building block manipulations.
* The use of Qwen-Instruct, Qwen-Physics, and Qwen-PhysRL suggests a specific architecture or framework.
* The Closed Loop GRPO is a key component, incorporating both physical properties (Wphys) and learned adaptations (LoRA Adapters).
* The training environment provides specific actions like "Right, Up, Quart Rot, Double" and "Down, Down, Slight Rot".
### Interpretation
The diagram outlines a system for training an AI agent to manipulate building blocks. The agent learns through a combination of supervised fine-tuning (SFT), physics-based simulation (Qwen-Physics), and reinforcement learning (Qwen-PhysRL). The Closed Loop GRPO likely represents a control mechanism that refines the agent's actions based on feedback from the environment. The "Action: Up" and "Update Shape B" elements suggest an iterative process where the agent takes actions to modify the shape of block B, and the system evaluates the results. The LoRA adapters likely allow for efficient adaptation to new tasks or environments. The entire workflow demonstrates a sophisticated approach to AI-driven manipulation of physical objects.