TECHNICAL ASSET FINGERPRINT
3fd11468c15fcfaa7d057324
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
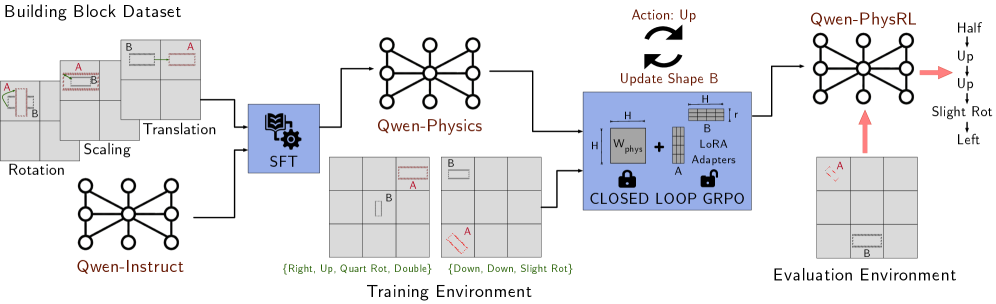
## Diagram: Qwen-Physics Reinforcement Learning Training Pipeline
### Overview
The image is a technical flowchart illustrating a machine learning training pipeline for a physics-aware model named "Qwen-Physics" and its reinforcement learning variant "Qwen-PhysRL." The diagram details the flow from a dataset, through supervised fine-tuning (SFT), into a training environment with a closed-loop reinforcement learning algorithm (GRPO), and finally to an evaluation environment. The process involves manipulating building blocks (labeled A and B) within a grid world.
### Components/Axes
The diagram is organized into several distinct regions and components, flowing generally from left to right.
**1. Header (Top-Left):**
* **Title:** "Building Block Dataset"
* **Content:** A series of grid-based examples showing transformations applied to two objects, labeled **A** (red outline) and **B** (blue outline).
* **Transformation Labels:** "Rotation", "Scaling", "Translation". These are positioned near the corresponding example grids.
**2. Initial Model & Training Start (Left):**
* **Model Icon:** A neural network diagram labeled **"Qwen-Instruct"**.
* **Process Block:** A blue box with a gear icon labeled **"SFT"** (Supervised Fine-Tuning). Arrows connect the "Building Block Dataset" and "Qwen-Instruct" to this block.
**3. Core Model (Center-Top):**
* **Model Icon:** A larger neural network diagram labeled **"Qwen-Physics"**. An arrow flows from the "SFT" block to this model.
**4. Training Environment (Center-Bottom):**
* **Title:** **"Training Environment"** (positioned at the bottom center).
* **Content:** Two example grid states.
* **Left Grid:** Shows object **A** (red) and object **B** (blue). Below it, a text string in green: **`{Right, Up, Quart Rot, Double}`**.
* **Right Grid:** Shows object **A** (red, rotated) and object **B** (blue). Below it, a text string in green: **`{Down, Down, Slight Rot}`**.
* **Flow:** An arrow points from "Qwen-Physics" to this environment.
**5. Learning Algorithm Block (Center-Right):**
* **Title:** **"CLOSED LOOP GRPO"** (inside a large blue box).
* **Internal Components:**
* A weight matrix labeled **`W_physics`** with a lock icon.
* A plus sign (`+`).
* A diagram labeled **"LoRA Adapters"** showing matrices **H**, **B**, **r**, and **A**.
* A lock icon next to the LoRA Adapters.
* **External Annotations:**
* Above the box: Two curved arrows forming a loop. Labels: **"Action: Up"** and **"Update Shape B"**.
* An arrow flows from the "Training Environment" into this block.
**6. Evaluation Environment & Final Model (Right):**
* **Model Icon:** A neural network diagram labeled **"Qwen-PhysRL"**. An arrow flows from the "CLOSED LOOP GRPO" block to this model.
* **Title:** **"Evaluation Environment"** (positioned at the bottom right).
* **Content:** A single grid state showing object **A** (red) and object **B** (blue). A red arrow points from this grid up to the "Qwen-PhysRL" model.
* **Output Action Sequence:** To the right of the "Qwen-PhysRL" model, a vertical list of actions in black text:
* **Half**
* **Up**
* **Up**
* **Slight Rot**
* **Left**
* A pink arrow points from the model to this list.
### Detailed Analysis
The diagram depicts a multi-stage training and evaluation process:
1. **Data & Initialization:** A "Building Block Dataset" containing examples of object transformations (Rotation, Scaling, Translation) is used. An initial model, "Qwen-Instruct," is the starting point.
2. **Supervised Fine-Tuning (SFT):** The dataset and the initial model are used to perform SFT, resulting in the "Qwen-Physics" model.
3. **Reinforcement Learning Loop:**
* The "Qwen-Physics" model interacts with a "Training Environment" consisting of grid worlds with objects A and B.
* The model's actions (e.g., `{Right, Up, Quart Rot, Double}`) are fed into a "CLOSED LOOP GRPO" (Group Relative Policy Optimization) algorithm.
* This algorithm contains a frozen physics weight matrix (`W_physics`) and trainable LoRA adapters, indicating parameter-efficient fine-tuning.
* The loop annotation ("Action: Up" / "Update Shape B") suggests the policy is updated based on the outcome of actions taken in the environment.
4. **Final Model & Evaluation:** The output of the GRPO training is the "Qwen-PhysRL" model. This model is then tested in a separate "Evaluation Environment." The diagram shows it generating a specific sequence of actions ("Half, Up, Up, Slight Rot, Left") in response to a given grid state.
### Key Observations
* **Two-Phase Training:** The pipeline clearly separates initial supervised learning (SFT) from subsequent reinforcement learning (GRPO).
* **Parameter Efficiency:** The use of LoRA Adapters within the GRPO block highlights a focus on efficient adaptation of the large "Qwen-Physics" model.
* **Environment Abstraction:** The "Training" and "Evaluation" environments are represented as grid worlds with simple objects (A, B) and discrete action spaces (movement, rotation).
* **Action Representation:** Actions are represented as sequences of commands (e.g., "Quart Rot" for quarter rotation, "Slight Rot").
* **Visual Coding:** Objects are consistently color-coded (A=red, B=blue) across all grids. The learning algorithm components are highlighted in a distinct blue box.
### Interpretation
This diagram outlines a methodology for imbuing a large language model (Qwen) with physics-based reasoning capabilities through a structured, two-stage training regimen.
* **Purpose:** The goal is to create a model ("Qwen-PhysRL") that can understand and predict the outcomes of physical interactions (like moving and rotating objects in a grid) and generate appropriate action sequences to achieve a desired state.
* **Relationships:** The "Building Block Dataset" provides the foundational knowledge of object transformations. SFT injects this knowledge into the base model. The RL loop (GRPO) then refines this knowledge by having the model actively experiment in an environment, learning from trial and error to optimize its policy, with the frozen `W_physics` likely preserving core physical understanding while the LoRA adapters learn task-specific strategies.
* **Notable Design Choice:** The "CLOSED LOOP" nature of the GRPO is critical. It implies the model's own actions and their results in the environment are used to continuously update its policy, creating a self-improving system for physical reasoning tasks. The separation of training and evaluation environments tests the model's ability to generalize its learned physics policies to new, unseen configurations.
DECODING INTELLIGENCE...