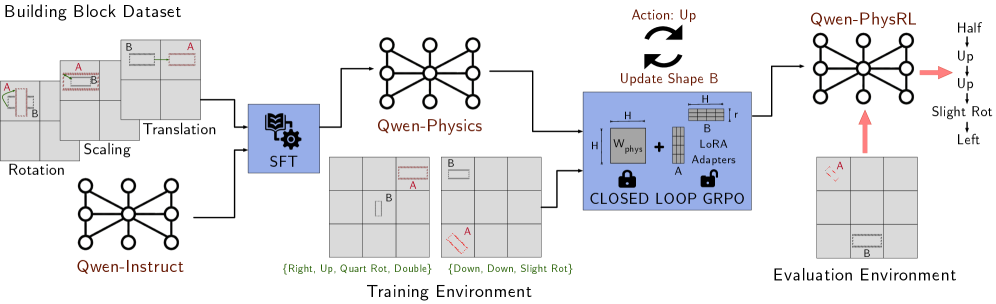
```markdown
## Diagram: PhysicsSimulation Training and Evaluation Pipeline
### Overview
The diagram illustrates a closed-loop physics simulation pipeline for training and evaluating a reinforcement learning (RL) agent. It integrates dataset generation, physics modeling, training with gradient-based optimization, and evaluation in a block-stacking environment. Key components include data augmentation, physics simulation, and action-space exploration.
### Components/Axes
1. **Building Block Dataset**
- Contains blocks labeled A and B with transformations:
- Rotation (e.g., 90°, 180°)
- Scaling (e.g., 0.5x, 2x)
- Translation (e.g., +1 unit, -2 units)
- Visualized as grid-aligned blocks with positional annotations.
2. **Qwen-Instruct**
- A graph-based node (central hub) connected to the Building Block Dataset.
- Represents instruction processing or policy initialization.
3. **Qwen-Physics**
- A graph-based node connected to Qwen-Instruct.
- Models physical interactions (e.g., gravity, friction) for block stacking.
4. **Training Environment**
- Contains:
- **SFT (Supervised Fine-Tuning)**: A blue box with a gear icon, processing transformed blocks.
- **Closed-Loop GRPO**: A locked box with "W_phys" (physics weight) and "LoRA Adapters" for parameter-efficient tuning.
- Actions include directional movements (Right, Up, Down) and rotations (Quart Rot, Slight Rot).
5. **Evaluation Environment**
- Labeled "Qwen-PhysRL" with a graph-based node.
- Actions: Up, Slight Rot, Left, Half Up.
- Visualized with arrows indicating action outcomes (e.g., "Up" moves block A upward).
6. **Action Feedback Loop**
- Arrows indicate iterative updates:
- "Update: Up" → "Update Shape B"
- Closed-loop GRPO adjusts physics weights (W_phys) based on evaluation results.
### Detailed Analysis
- **Dataset Generation**: Blocks A and B undergo randomized transformations (rotation, scaling, translation) to create diverse training scenarios.
- **Physics Modeling**: Qwen-Physics simulates real-world constraints (e.g., block stability, collision detection).
- **Training**:
- SFT initializes the policy using supervised examples.
- Closed-loop GRPO refines the policy using LoRA adapters to optimize physics-aware actions.
- **Evaluation**: Qwen-PhysRL tests the agent’s ability to execute precise actions (e.g., "Slight Rot" rotates block A 45°).
### Key Observations
- **Action-Space Complexity**: The evaluation environment includes both discrete (Up/Down) and continuous (Slight Rot) actions, suggesting hybrid control strategies.
- **Physics Integration**: LoRA adapters in the closed-loop GRPO indicate dynamic adjustment of physics parameters during training.
- **Block Interactions**: Block B is frequently updated ("Update Shape B"), implying it acts as a movable target or obstacle.
### Interpretation
This pipeline demonstrates a physics-informed RL framework for robotic manipulation tasks. The closed-loop GRPO with Lo