## Line Graph: Training Accuracy
### Overview
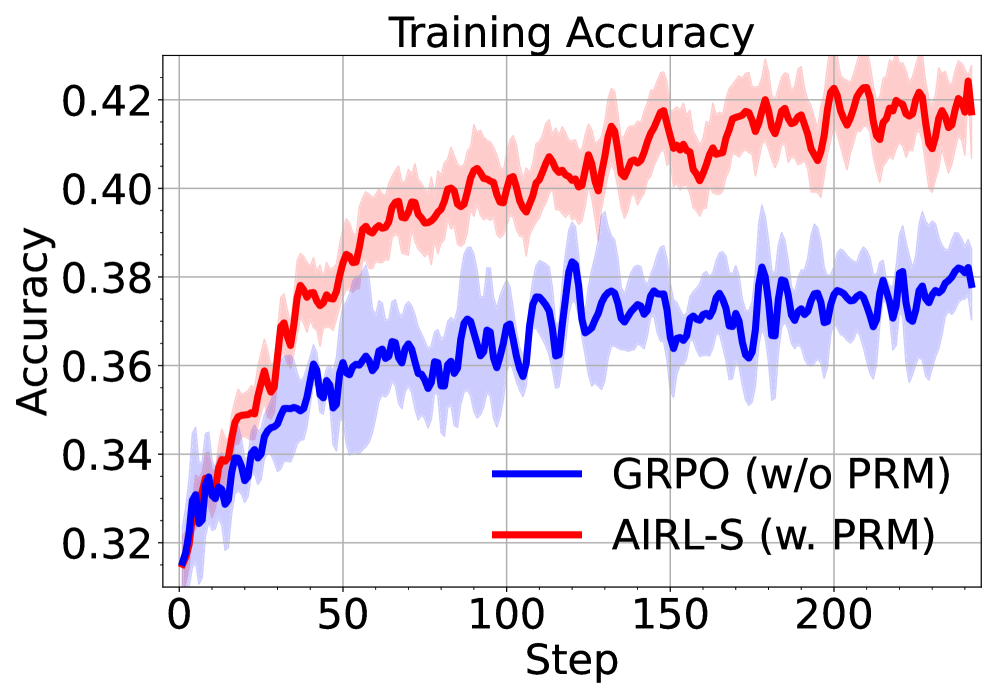
The image depicts a line graph comparing the training accuracy of two models over 200 training steps. The blue line represents "GRPO (w/o PRM)" and the red line represents "AIRL-S (w. PRM)." Both lines show increasing trends, but the red line consistently outperforms the blue line, with shaded regions indicating variability in accuracy.
### Components/Axes
- **X-axis (Step)**: Ranges from 0 to 200 in increments of 50.
- **Y-axis (Accuracy)**: Ranges from 0.32 to 0.42 in increments of 0.02.
- **Legend**: Located at the bottom-right corner.
- Blue line: "GRPO (w/o PRM)"
- Red line: "AIRL-S (w. PRM)"
- **Shaded Regions**: Gray areas around each line represent variability (likely confidence intervals or standard error).
### Detailed Analysis
1. **GRPO (w/o PRM) [Blue Line]**:
- Starts at ~0.32 accuracy at step 0.
- Gradually increases to ~0.38 by step 200.
- Exhibits moderate fluctuations (e.g., dips to ~0.34 at step 50, peaks at ~0.37 at step 150).
- Shaded region spans ~0.32–0.38, indicating variability.
2. **AIRL-S (w. PRM) [Red Line]**:
- Starts at ~0.34 accuracy at step 0.
- Increases steadily to ~0.42 by step 200.
- Shows sharper peaks (e.g., ~0.41 at step 100, ~0.42 at step 200).
- Shaded region spans ~0.34–0.42, with higher variability in later steps.
### Key Observations
- The red line (AIRL-S with PRM) consistently outperforms the blue line (GRPO without PRM) across all steps.
- Both models show upward trends, but AIRL-S with PRM achieves higher final accuracy (~0.42 vs. ~0.38).
- Variability (shaded regions) increases for both models as training progresses, suggesting diminishing stability in later steps.
### Interpretation
The data suggests that incorporating PRM (Proximal Regularization Method) in the AIRL-S model significantly improves training accuracy compared to the GRPO model without PRM. The steeper and more stable ascent of the red line indicates that PRM may enhance model convergence or reduce overfitting during training. The increasing variability in later steps for both models could reflect challenges in maintaining accuracy as training complexity grows. This highlights the potential value of PRM in optimizing training dynamics for reinforcement learning tasks.