TECHNICAL ASSET FINGERPRINT
401a265b44181348201fc906
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
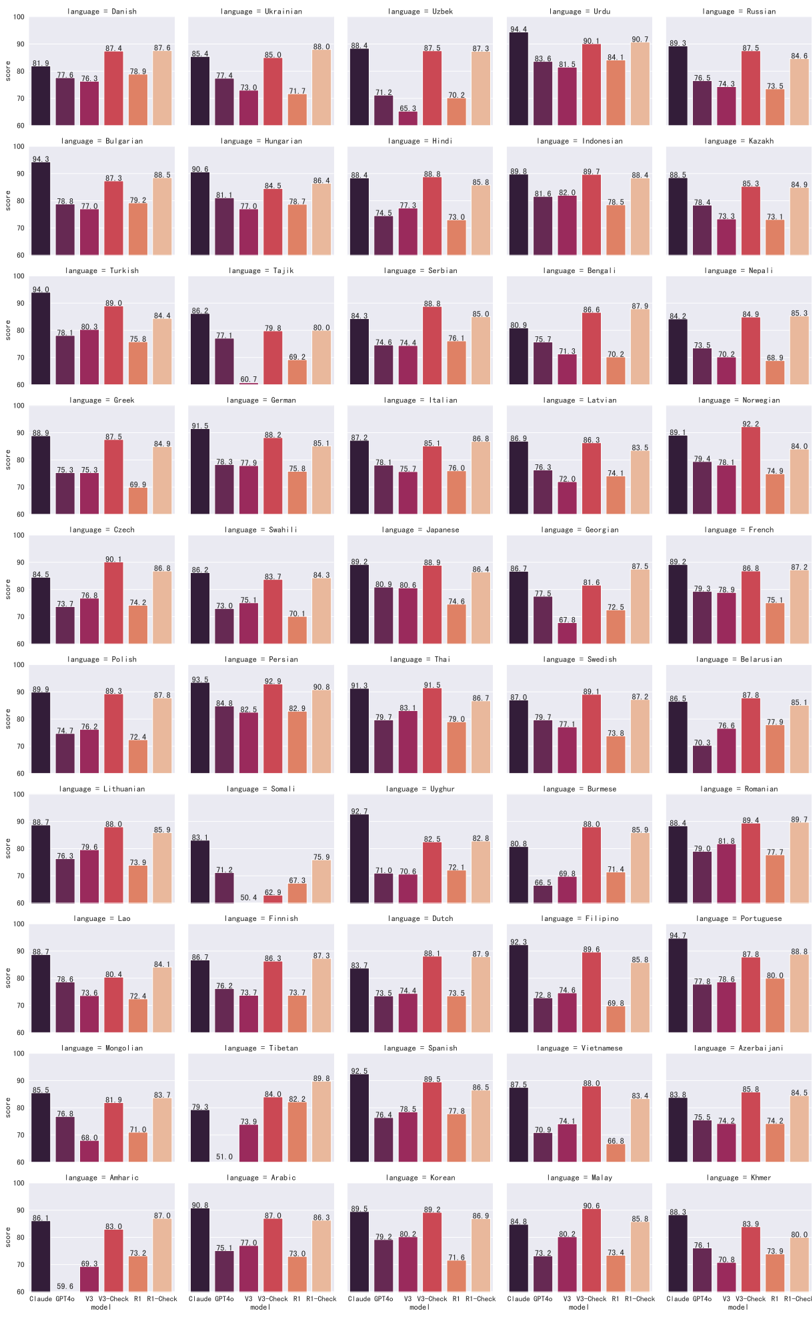
## Bar Chart: Language Model Performance Comparison
### Overview
The image presents a series of bar charts, each comparing the performance of different language models (Claude GPT4o, V3, V3-Check, R1, and R1-Check) across various languages. The y-axis represents the "score," ranging from 60 to 100. Each chart focuses on a specific language, indicated by the "language =" label above the chart. The x-axis represents the different language models.
### Components/Axes
* **Y-axis:** "score" ranging from 60 to 100, with tick marks at intervals of 10.
* **X-axis:** Categorical, representing the language models: Claude GPT4o, V3, V3-Check, R1, and R1-Check.
* **Chart Title:** "language = [Language Name]" for each individual chart.
* **Bars:** Each bar represents the score of a specific language model for the given language. The bars are colored in shades of purple and orange.
### Detailed Analysis or ### Content Details
Here's a breakdown of the data for each language, including the approximate scores for each model:
**Row 1**
* **Language = Danish:**
* Claude GPT4o: 81.9
* V3: 77.6
* V3-Check: 76.3
* R1: 87.4
* R1-Check: 87.6
* **Language = Ukrainian:**
* Claude GPT4o: 85.4
* V3: 77.4
* V3-Check: 73.0
* R1: 71.7
* R1-Check: 88.0
* **Language = Uzbek:**
* Claude GPT4o: 88.4
* V3: 71.2
* V3-Check: 65.3
* R1: 87.5
* R1-Check: 87.3
* **Language = Urdu:**
* Claude GPT4o: 94.4
* V3: 83.6
* V3-Check: 81.5
* R1: 90.1
* R1-Check: 90.7
* **Language = Russian:**
* Claude GPT4o: 84.8
* V3: 76.5
* V3-Check: 74.3
* R1: 73.5
* R1-Check: 84.6
**Row 2**
* **Language = Bulgarian:**
* Claude GPT4o: 94.3
* V3: 78.8
* V3-Check: 77.0
* R1: 87.3
* R1-Check: 88.5
* **Language = Hungarian:**
* Claude GPT4o: 90.6
* V3: 81.1
* V3-Check: 84.5
* R1: 78.7
* R1-Check: 86.4
* **Language = Hindi:**
* Claude GPT4o: 88.4
* V3: 77.3
* V3-Check: 74.5
* R1: 88.8
* R1-Check: 85.8
* **Language = Indonesian:**
* Claude GPT4o: 89.8
* V3: 81.6
* V3-Check: 82.0
* R1: 89.7
* R1-Check: 88.4
* **Language = Kazakh:**
* Claude GPT4o: 88.4
* V3: 73.3
* V3-Check: 73.1
* R1: 85.3
* R1-Check: 84.9
**Row 3**
* **Language = Turkish:**
* Claude GPT4o: 94.0
* V3: 78.1
* V3-Check: 80.3
* R1: 89.0
* R1-Check: 84.4
* **Language = Tajik:**
* Claude GPT4o: 86.2
* V3: 77.1
* V3-Check: 79.8
* R1: 60.7
* R1-Check: 80.0
* **Language = Serbian:**
* Claude GPT4o: 84.3
* V3: 74.6
* V3-Check: 74.4
* R1: 88.8
* R1-Check: 85.0
* **Language = Bengali:**
* Claude GPT4o: 80.9
* V3: 71.3
* V3-Check: 70.2
* R1: 86.6
* R1-Check: 87.9
* **Language = Nepali:**
* Claude GPT4o: 84.2
* V3: 73.5
* V3-Check: 70.2
* R1: 85.3
* R1-Check: 85.3
**Row 4**
* **Language = Greek:**
* Claude GPT4o: 88.9
* V3: 75.3
* V3-Check: 75.3
* R1: 87.5
* R1-Check: 84.9
* **Language = German:**
* Claude GPT4o: 91.5
* V3: 78.3
* V3-Check: 77.9
* R1: 60.7
* R1-Check: 85.1
* **Language = Italian:**
* Claude GPT4o: 87.2
* V3: 78.1
* V3-Check: 75.7
* R1: 85.1
* R1-Check: 86.8
* **Language = Latvian:**
* Claude GPT4o: 86.9
* V3: 76.3
* V3-Check: 72.0
* R1: 86.3
* R1-Check: 83.5
* **Language = Norwegian:**
* Claude GPT4o: 89.1
* V3: 79.4
* V3-Check: 78.1
* R1: 74.9
* R1-Check: 84.0
**Row 5**
* **Language = Czech:**
* Claude GPT4o: 84.5
* V3: 73.7
* V3-Check: 76.8
* R1: 90.1
* R1-Check: 86.8
* **Language = Swahili:**
* Claude GPT4o: 86.2
* V3: 73.0
* V3-Check: 75.1
* R1: 70.1
* R1-Check: 84.3
* **Language = Japanese:**
* Claude GPT4o: 89.2
* V3: 80.9
* V3-Check: 80.6
* R1: 88.9
* R1-Check: 86.4
* **Language = Georgian:**
* Claude GPT4o: 86.7
* V3: 78.3
* V3-Check: 67.8
* R1: 81.6
* R1-Check: 87.5
* **Language = French:**
* Claude GPT4o: 89.2
* V3: 79.3
* V3-Check: 78.9
* R1: 75.1
* R1-Check: 87.2
**Row 6**
* **Language = Polish:**
* Claude GPT4o: 89.9
* V3: 74.7
* V3-Check: 76.2
* R1: 90.1
* R1-Check: 86.8
* **Language = Persian:**
* Claude GPT4o: 93.5
* V3: 84.8
* V3-Check: 82.5
* R1: 82.9
* R1-Check: 90.8
* **Language = Thai:**
* Claude GPT4o: 91.3
* V3: 79.7
* V3-Check: 83.1
* R1: 79.0
* R1-Check: 86.7
* **Language = Swedish:**
* Claude GPT4o: 89.1
* V3: 77.1
* V3-Check: 73.8
* R1: 87.2
* R1-Check: 85.1
* **Language = Belarusian:**
* Claude GPT4o: 86.5
* V3: 76.6
* V3-Check: 70.3
* R1: 77.8
* R1-Check: 85.1
**Row 7**
* **Language = Lithuanian:**
* Claude GPT4o: 88.7
* V3: 76.3
* V3-Check: 79.6
* R1: 88.0
* R1-Check: 85.9
* **Language = Somali:**
* Claude GPT4o: 83.1
* V3: 71.2
* V3-Check: 50.4
* R1: 62.9
* R1-Check: 75.9
* **Language = Uyghur:**
* Claude GPT4o: 92.7
* V3: 71.0
* V3-Check: 70.6
* R1: 72.1
* R1-Check: 82.8
* **Language = Burmese:**
* Claude GPT4o: 80.8
* V3: 66.5
* V3-Check: 69.8
* R1: 88.0
* R1-Check: 85.9
* **Language = Romanian:**
* Claude GPT4o: 88.4
* V3: 79.0
* V3-Check: 81.8
* R1: 77.7
* R1-Check: 89.7
**Row 8**
* **Language = Lao:**
* Claude GPT4o: 88.7
* V3: 78.6
* V3-Check: 73.6
* R1: 80.4
* R1-Check: 84.1
* **Language = Finnish:**
* Claude GPT4o: 83.1
* V3: 76.2
* V3-Check: 73.7
* R1: 67.3
* R1-Check: 75.9
* **Language = Dutch:**
* Claude GPT4o: 92.7
* V3: 73.5
* V3-Check: 74.4
* R1: 88.1
* R1-Check: 87.9
* **Language = Filipino:**
* Claude GPT4o: 92.3
* V3: 74.6
* V3-Check: 74.4
* R1: 89.6
* R1-Check: 85.8
* **Language = Portuguese:**
* Claude GPT4o: 94.7
* V3: 77.8
* V3-Check: 80.0
* R1: 87.6
* R1-Check: 88.8
**Row 9**
* **Language = Mongolian:**
* Claude GPT4o: 85.5
* V3: 76.8
* V3-Check: 68.0
* R1: 81.9
* R1-Check: 83.7
* **Language = Tibetan:**
* Claude GPT4o: 83.7
* V3: 73.9
* V3-Check: 78.1
* R1: 51.0
* R1-Check: 89.8
* **Language = Spanish:**
* Claude GPT4o: 92.5
* V3: 76.4
* V3-Check: 78.5
* R1: 89.5
* R1-Check: 86.5
* **Language = Vietnamese:**
* Claude GPT4o: 94.7
* V3: 70.9
* V3-Check: 74.1
* R1: 89.6
* R1-Check: 85.8
* **Language = Azerbaijani:**
* Claude GPT4o: 87.5
* V3: 75.5
* V3-Check: 74.2
* R1: 80.0
* R1-Check: 84.5
**Row 10**
* **Language = Amharic:**
* Claude GPT4o: 86.1
* V3: 69.3
* V3-Check: 59.6
* R1: 83.0
* R1-Check: 87.0
* **Language = Arabic:**
* Claude GPT4o: 90.8
* V3: 75.1
* V3-Check: 77.0
* R1: 73.0
* R1-Check: 86.3
* **Language = Korean:**
* Claude GPT4o: 89.5
* V3: 79.2
* V3-Check: 80.2
* R1: 89.2
* R1-Check: 86.9
* **Language = Malay:**
* Claude GPT4o: 90.6
* V3: 73.2
* V3-Check: 73.4
* R1: 88.8
* R1-Check: 85.8
* **Language = Khmer:**
* Claude GPT4o: 84.8
* V3: 76.1
* V3-Check: 70.8
* R1: 73.9
* R1-Check: 80.0
### Key Observations
* Claude GPT4o generally has high scores across all languages.
* V3 and V3-Check models tend to have lower scores compared to Claude GPT4o, R1, and R1-Check.
* R1 and R1-Check models show variability in performance across different languages.
* There are some languages (e.g., Somali, Tibetan) where the performance of certain models (e.g., R1) is significantly lower.
### Interpretation
The data suggests that Claude GPT4o is a robust language model with consistently high performance across a wide range of languages. The V3 and V3-Check models appear to be less effective, indicating potential areas for improvement. The R1 and R1-Check models show promise but also exhibit some inconsistencies, suggesting that their performance may be more sensitive to the specific language being processed. The significant performance dips for certain models in specific languages highlight potential biases or limitations in the training data or model architecture. Further investigation into these outliers could provide valuable insights for model refinement and optimization.
DECODING INTELLIGENCE...