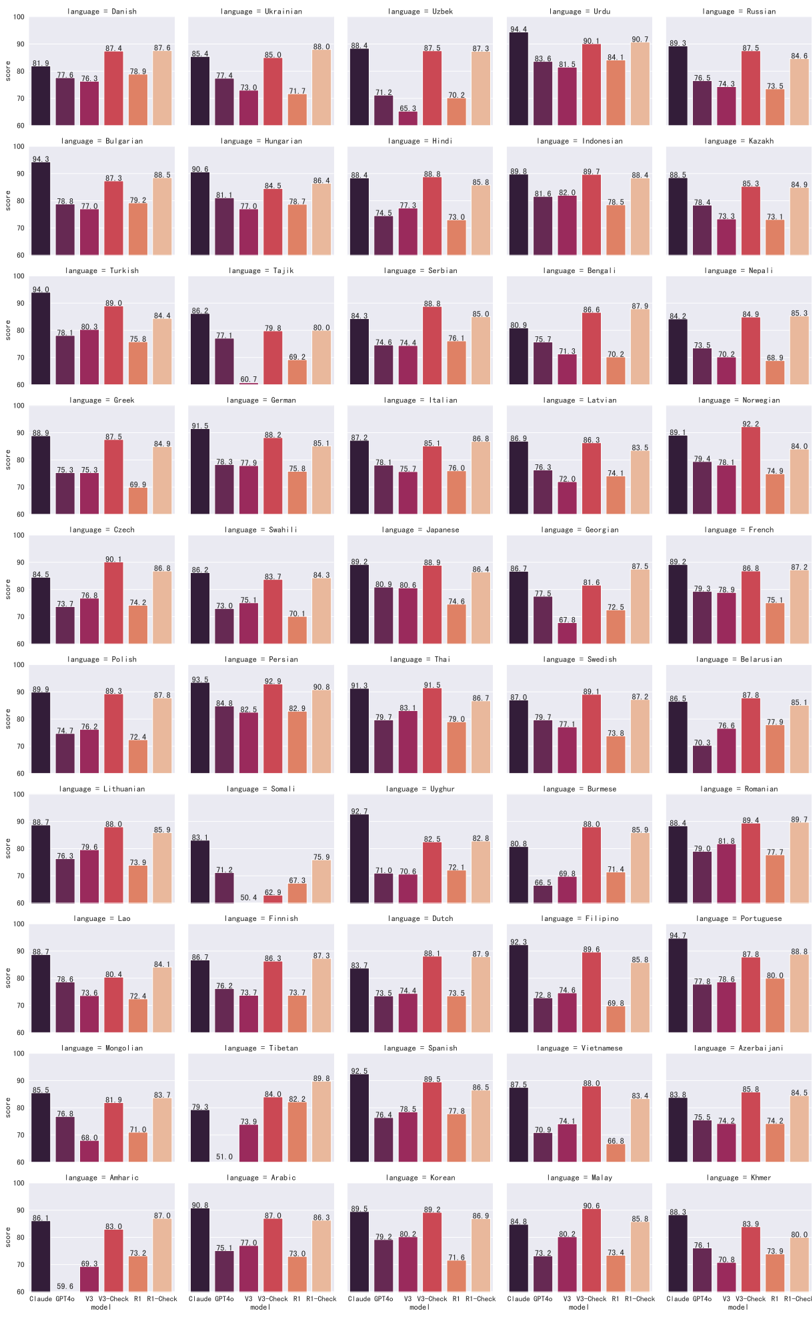
## Bar Chart Grid: Model Performance Across Languages
### Overview
The image displays a grid of bar charts comparing the performance of four AI models (Claude GPT4o, V3-Check, R1-Check, and another R1-Check) across 30+ languages. Each chart represents a single language, with four bars indicating the score for each model. The x-axis represents a score scale (60–100), and the y-axis lists languages in alphabetical order. The legend maps colors to models: dark purple (Claude GPT4o), purple (V3-Check), red (R1-Check), and orange (R1-Check).
### Components/Axes
- **X-axis**: Labeled "score" with a range from 60 to 100.
- **Y-axis**: Labeled "language," listing languages such as Danish, Ukrainian, Uzbek, Russian, Turkish, Tajik, Greek, German, Czech, Polish, Lithuanian, Latvian, Norwegian, French, Georgian, Thai, Swedish, Burmese, Romanian, Portuguese, Vietnamese, Azerbaijani, Korean, Malay, Khmer, Arabic, and others.
- **Legend**: Positioned at the bottom-right of the grid, with four color-coded models:
- **Dark purple**: Claude GPT4o
- **Purple**: V3-Check
- **Red**: R1-Check
- **Orange**: R1-Check (duplicate label, possibly a typo).
### Detailed Analysis
- **Structure**: Each language has a vertical bar chart with four bars (one per model). Scores are approximate, with values ranging from ~50 to ~95.
- **Color Coding**:
- **Claude GPT4o** (dark purple) often has the highest scores in many languages (e.g., Danish: ~94.3, Ukrainian: ~85.4).
- **V3-Check** (purple) shows moderate performance, with scores like ~77.4 (Danish) and ~73.0 (Ukrainian).
- **R1-Check** (red/orange) varies widely, with some languages showing lower scores (e.g., ~50.4 for Tajik in V3-Check).
- **Notable Patterns**:
- **Claude GPT4o** consistently outperforms other models in most languages.
- **R1-Check** (orange) has the lowest scores in several languages (e.g., Tajik: ~50.4, Arabic: ~51.0).
- **V3-Check** (purple) shows mid-range performance, with scores like ~73.3 (Danish) and ~70.2 (Ukrainian).
### Key Observations
- **Highest Scores**: Claude GPT4o dominates in languages like Danish (~94.3), Ukrainian (~85.4), and Russian (~89.3).
- **Lowest Scores**: R1-Check (orange) underperforms in Tajik (~50.4), Arabic (~51.0), and Burmese (~66.5).
- **Model Variability**: Scores differ significantly across models, suggesting language-specific strengths/weaknesses.
### Interpretation
The data suggests that **Claude GPT4o** is the most robust model across languages, while **R1-Check** (orange) struggles in certain linguistic contexts. The duplicate "R1-Check" label in the legend may indicate a data entry error or a distinct variant of the model. The grid highlights the importance of model selection based on target language, as performance varies widely. For example, Claude GPT4o excels in European and Asian languages, whereas R1-Check (orange) lags in South Asian and Middle Eastern languages. This could reflect differences in training data, architecture, or fine-tuning for specific language groups.