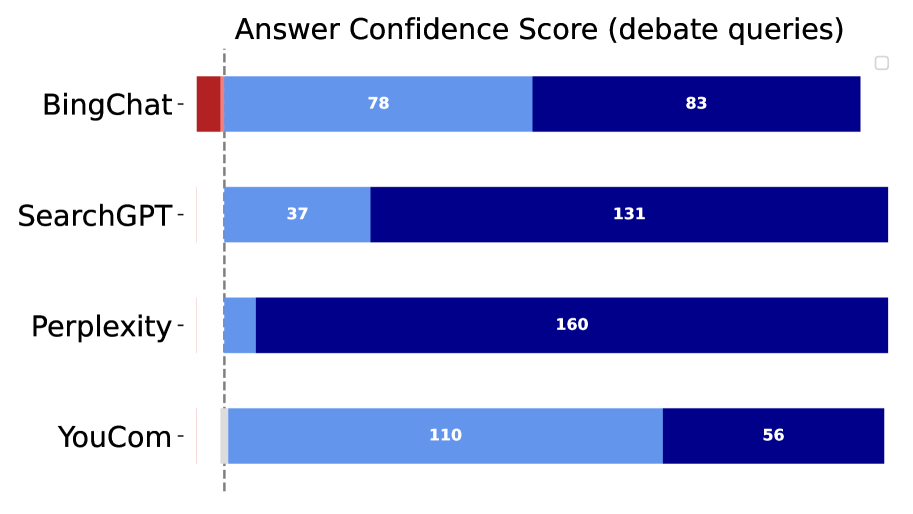
## Horizontal Bar Chart: Answer Confidence Score (debate queries)
### Overview
The chart compares answer confidence scores for four AI systems (BingChat, SearchGPT, Perplexity, YouCom) across two categories: "Correct" (light blue) and "Incorrect" (dark blue) responses to debate queries. Each bar represents confidence scores, with numerical values displayed on the bars.
### Components/Axes
- **Y-Axis**: Labeled with AI system names (BingChat, SearchGPT, Perplexity, YouCom) in descending order from top to bottom.
- **X-Axis**: Labeled "Answer Confidence Score (debate queries)" with a dashed vertical line at 0.
- **Legend**: Located on the right, with:
- Light blue: "Correct" (correct answers)
- Dark blue: "Incorrect" (incorrect answers)
- **Bars**: Horizontal bars for each AI system, split into two segments (light blue + dark blue) representing correct/incorrect confidence scores.
### Detailed Analysis
1. **BingChat**:
- Correct: 78 (light blue)
- Incorrect: 83 (dark blue)
- Total: 161
2. **SearchGPT**:
- Correct: 37 (light blue)
- Incorrect: 131 (dark blue)
- Total: 168
3. **Perplexity**:
- Correct: 160 (light blue)
- Incorrect: 56 (dark blue)
- Total: 216
4. **YouCom**:
- Correct: 110 (light blue)
- Incorrect: 56 (dark blue)
- Total: 166
### Key Observations
- **Perplexity** has the highest correct confidence score (160) and the lowest incorrect score (56), indicating strong performance.
- **SearchGPT** has the lowest correct score (37) and the highest incorrect score (131), suggesting poor confidence calibration.
- **YouCom** and **BingChat** have similar total confidence scores (~160-166), but YouCom has a better correct-to-incorrect ratio (110:56 vs. 78:83).
- All systems show a clear separation between correct and incorrect confidence scores, with no overlap between the two categories.
### Interpretation
The data suggests that **Perplexity** is the most reliable AI system for debate queries, with the highest confidence in correct answers and the lowest in incorrect ones. **SearchGPT** performs poorly, with a significant disparity between correct and incorrect confidence scores. **YouCom** and **BingChat** show moderate performance, but YouCom’s higher correct score (110 vs. 78) indicates better calibration. The chart highlights the importance of confidence calibration in AI systems, as miscalibrated confidence can lead to over- or under-reliance on incorrect answers. The dashed vertical line at 0 may represent a baseline threshold, but its significance is unclear without additional context.